XiangShan ICache 设计文档
- 版本:V2R2
- 状态:OK
- 日期:2025/03/07
- commit:4b2c87ba1d7965f6f2b0a396be707a6e2f6fb345
术语说明
| 缩写 | 全称 | 描述 |
|---|---|---|
| ICache/I$ | Instruction Cache | L1 指令缓存 |
| DCache/D$ | Data Cache | L1 数据缓存 |
| L2 Cache/L2$ | Level Two Cache | L2 缓存 |
| IFU | Instruction Fetch Unit | 取指单元 |
| ITLB | Instruction Translation Lookaside Buffer | 地址翻译缓冲 |
| PMP | Physical Memory Protection | 物理内存保护模块 |
| PMA | Physical Memory Attribute | 物理内存属性模块(是 PMP 的一部分) |
| BEU | Bus Error Unit | 总线错误单元 |
| FDIP | Fetch-directed Instruction Prefetch | 取指导向指令预取 |
| MSHR | Miss Status Holding Register | 缺失状态保持寄存器 |
| a/(g)pf | Access / (Guest) Page Fault | 访问错误 / (客户机)页错误 |
| v/(g)paddr | Virtual / (Guest) Physical Address | 虚拟地址 / (客户机)物理地址 |
| PBMT | Page-Based Memory Types | 基于页的内存类型,见特权手册 Svpbmt 扩展 |
子模块列表
| 子模块 | 描述 |
|---|---|
| MainPipe | 主流水线 |
| IPrefetchPipe | 预取流水线 |
| WayLookup | 元数据缓冲队列 |
| MetaArray | 元数据 SRAM |
| DataArray | 数据 SRAM |
| MissUnit | 缺失处理单元 |
| Replacer | 替换策略单元 |
| CtrlUnit | 控制单元,目前仅用于控制错误校验/错误注入功能 |
设计规格
- 缓存指令数据
- 缺失时通过 tilelink 总线向 L2 请求数据
- 软件维护 L1 I/D Cache 一致性(
fence.i) - 支持跨 cacheline (预)取指请求
- 支持冲刷(bpu redirect、backend redirect、
fence.i) - 支持预取指请求
- 硬件预取为 FDIP 预取算法
- 软件预取为 Zicbop 扩展
prefetch.i指令 - 支持可配置的替换算法
- 支持可配置的缺失状态寄存器数量
- 支持检查地址翻译错误、物理内存保护错误
- 支持错误检查 & 错误恢复 & 错误注入1
- 默认采用 parity code
- 通过从 L2 重取实现错误恢复
- 软件可通过 MMIO 空间访问的错误注入控制寄存器
- DataArray 支持分 bank 存储,细存储粒度实现低功耗
参数列表
| 参数 | 默认值 | 描述 | 要求 |
|---|---|---|---|
| nSets | 256 | SRAM set 数量 | 2 的幂次 |
| nWays | 4 | SRAM way 数量 | |
| nFetchMshr | 4 | 取指 MSHR 的数量 | |
| nPrefetchMshr | 10 | 预取 MSHR 的数量 | |
| nWayLookupSize | 32 | WayLookup 深度,同时可以反压限制预取最大距离 | |
| DataCodeUnit | 64 | 校验单元大小,单位为 bit,每 64bit 对应 1bit 的校验位 | |
| ICacheDataBanks | 8 | cacheline 划分 bank 数量 | |
| ICacheDataSRAMWidth | 66 | DataArray 基本 SRAM 的宽度 | 大于每 bank 的 data 和 code 宽度之和 |
功能概述
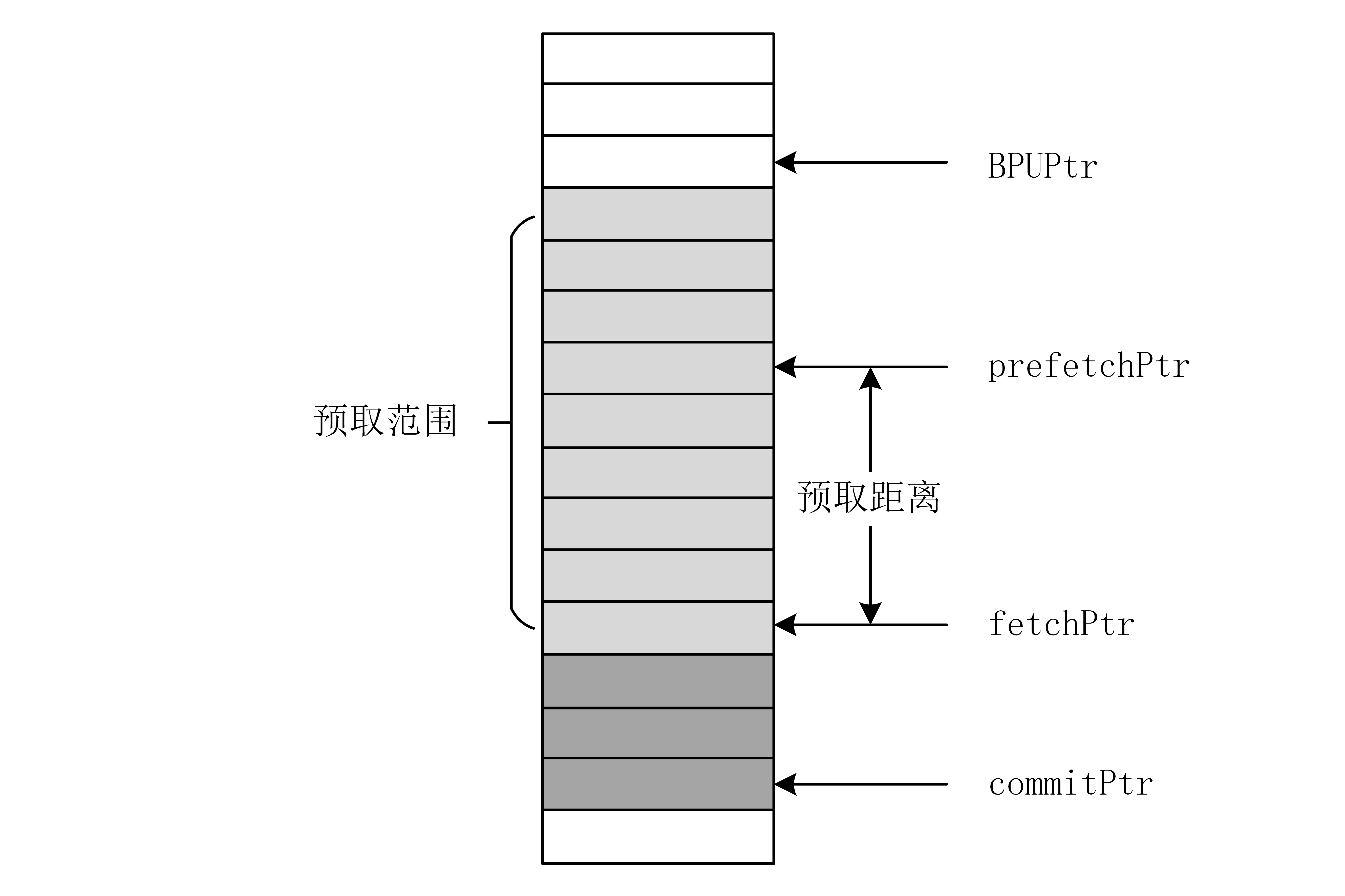
FTQ 中存储着 BPU 生成的预测块,fetchPtr 指向取指预测块,prefetchPtr 指向预取预测块,当复位时 prefetchPtr 与 fetchPtr 相同,每成功发送一次取指请求时 fetchPtr++,每成功发送一次预取请求时 prefetchPtr++。详细说明见FTQ 设计文档。
ICache 结构如下图所示。有 MainPipe 和 IPrefetchPipe 两个流水线,MainPipe 接收来自 FTQ 的取指请求,IPrefetchPipe 接收来自 FTQ/MemBlock 的硬/软件预取请求。对于预取请求,IPrefetch 对 MetaArray 进行查询,将元数据(在哪一路命中、ECC 校验码、是否发生异常等)存储到 WayLookup 中,如果该请求缺失,就发送至 MissUnit 进行预取。对于取指请求,MainPipe 首先从 WayLookup 中读取命中信息,如果 WayLookup 中没有可用信息,MainPipe 就会阻塞,直至 IPrefetchPipe 将信息写入 WayLookup 中,该方案将 MetaArray 和 DataArray 的访问分离,一次只访问 DataArray 单路,实现了较低的功耗,代价是产生了一个周期的重定向延迟。
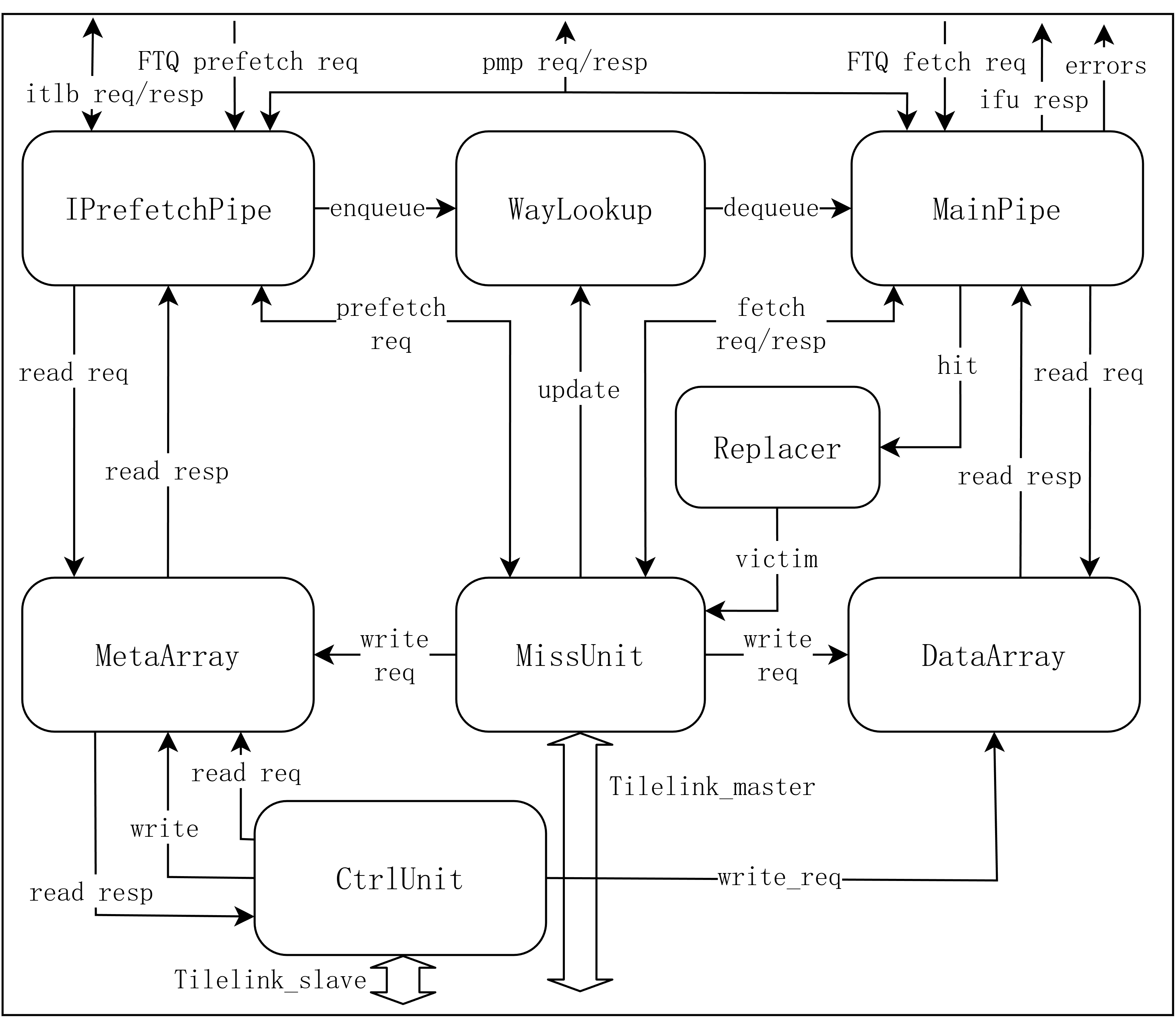
MissUnit 处理来自 MainPipe 的取指请求和来自 IPrefetchPipe 的预取请求,通过 MSHR 进行管理,所有 MSHR 公用一组数据寄存器以减少面积。
Replacer 为替换器,默认采用 PLRU 替换策略,接收来自 MainPipe 的命中更新,向 MissUnit 提供待替换的 waymask。
MetaArray 分为奇偶两个 bank,用于支持跨 cacheline 的双行访问。
DataArray 中的 cacheline 默认分为 8 个 bank 存储,每个 bank 中存储的有效数据为 64bit,另外对于每 64bit 还需要 1bit 的校验位,由于 65bit 宽度的 SRAM 表现不好,所以选用 256*66bit 的 SRAM 作为基本单元,一共有 32 个这样的基本单元。一次访问需要 34Byte 的指令数据,每次需要访问 5 个 bank(\(8\times5>34\)),根据起始地址进行选择。
功能详述
(预)取指请求
FTQ 分别把(预)取指请求发送到(预)取指流水线进行处理。如前所述,由 IPrefetch 对 MetaArray 和 ITLB 进行查询,将元数据(在哪一路命中、ECC 校验码、是否发生异常等)在 IPrefetchPipe s1 流水级存储到 WayLookup 中,以供 MainPipe s0 流水级读取。
在上电解复位/重定向时,由于 WayLookup 为空,而 FTQ 的 prefetchPtr、fetchPtr 复位到同一位置,MainPipe s0 流水级不得不阻塞等待 IPrefetchPipe s1 流水级的写入,这引入了一拍的额外重定向延迟。但随着 BPU 向 FTQ 填充预测块的进行和 MainPipe/IFU 因各种原因阻塞(e.g. miss、IBuffer 满),IPrefetchPipe 将工作在 MainPipe 前(prefetchPtr > fetchPtr),而 WayLookup 中也会有足够的元数据,此时 MainPipe s0 级和 IPrefetchPipe s0 级的工作将是并行的。
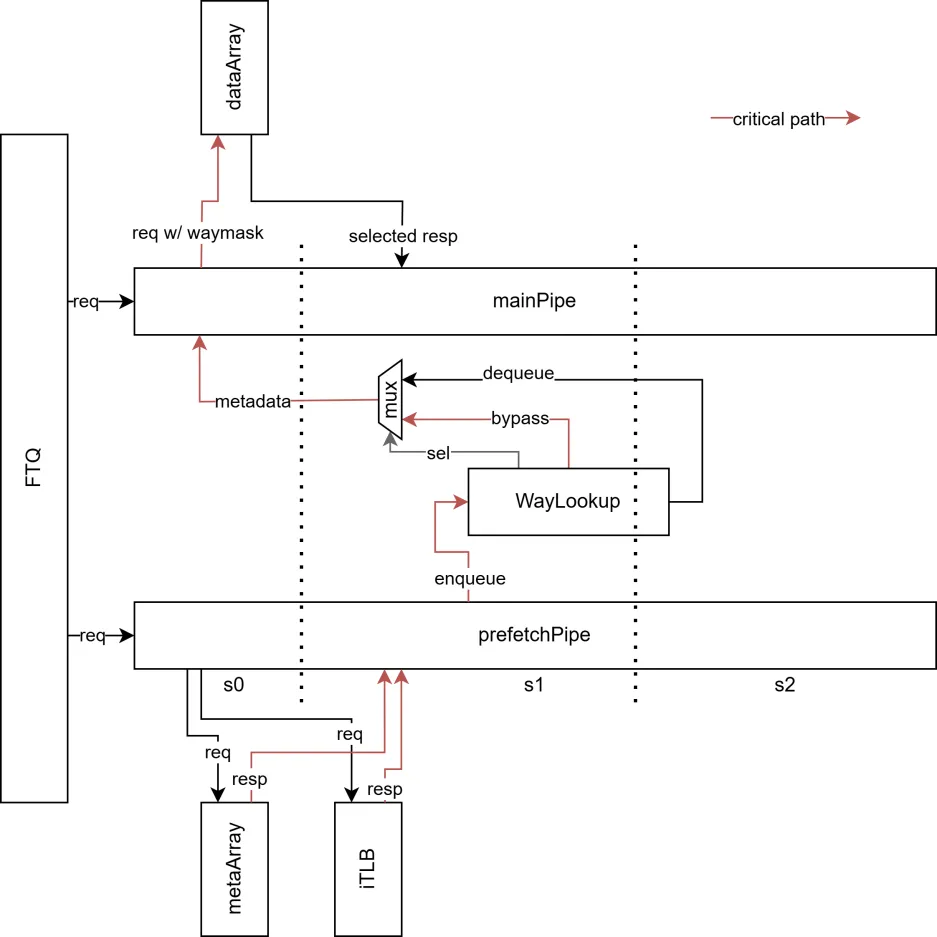
详细的取指过程见MainPipe 子模块文档、IPrefetchPipe 子模块文档和WayLookup 子模块文档。
硬件预取与软件预取
V2R2 后,ICache 可能接受两个来源的预取请求:
- 来自 Ftq 的硬件预取请求,基于 FDIP 算法。
- 来自 Memblock 中 LoadUint 的软件预取请求,其本质是 Zicbop 扩展中的 prefetch.i 指令,请参考 RISC-V CMO 手册。
然而,PrefetchPipe 每周期仅可以处理一个预取请求,故需要进行仲裁。ICache 顶层负责缓存软件预取请求,并与来自 Ftq 的硬件预取请求二选一送往 PrefetchPipe,软件预取请求的优先级高于硬件预取请求。
逻辑上来说,每个 LoadUnit 都有可能发出软件预取请求,因此每周期至多会有 LoadUnit 数量(目前默认参数为LduCnt=3)个软件预取请求。但出于实现成本和性能收益考量,ICache 每周期至多仅接收并处理一个,多余的会被丢弃,端口下标最小的优先。此外,若 PrefetchPipe 阻塞,而 ICache 内已经缓存了一个软件预取请求,那么原先的软件预取请求将被覆盖。
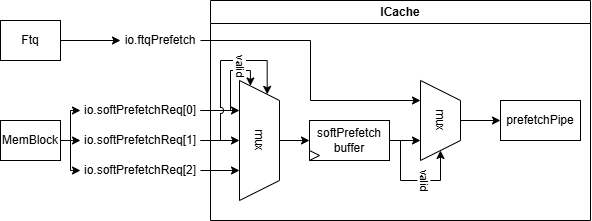
发送到 PrefetchPipe 后,软件预取请求的处理和硬件预取请求的处理几乎是一致的,除了: - 软件预取请求不会影响控制流,即不会发送到 MainPipe(和后续的 Ifu、IBuffer 等环节),仅做:1) 判断是否 miss 或异常;2) 若 miss 且无异常,发送到 MissUnit 做预取指并重填 SRAM。
关于 PrefetchPipe 的细节请查看子模块文档。
异常传递/特殊情况处理
ICache 负责对取指请求的地址进行权限检查(通过 ITLB 和 PMP),接收 L2 的响应,过程中可能出现的异常有:
| 来源 | 异常 | 描述 | 处理 |
|---|---|---|---|
| ITLB | af | 虚拟地址翻译过程出现访问错误 | 禁止取指,标记取指块为 af,经 IFU、IBuffer 发送到后端处理 |
| ITLB | gpf | 客户机页错误 | 禁止取指,标记取指块为 gpf,经 IFU、IBuffer 发送到后端处理,将有效的 gpaddr 和 isForNonLeafPTE 发送到后端的 GPAMem 以备使用 |
| ITLB | pf | 页错误 | 禁止取指,标记取指块为 pf,经 IFU、IBuffer 发送到后端处理 |
| backend | af/pf/gpf | 同 ITLB af/gpf/pf | 同 ITLB af/gpf/pf |
| PMP | af | 物理地址无权限访问 | 同 ITLB af |
| MissUnit | L2 corrupt | L2 cache 响应 corrupt | 标记取指块为 af,经 IFU、IBuffer 发送到后端处理 |
需要指出,对于一般的取指流程来说,并不存在 backend 异常这一项。但 XiangShan 出于节省硬件资源的考虑,在前端传递的 pc 只有 41 / 50 bit(Sv39*4 / Sv48*4),而对于 jr、jalr 等指令,跳转目标来源于 64 bit 寄存器。根据 RISC-V 规范,高位非全0或全1时的地址不合法,需要引发异常,这一检查只能由后端完成,并随同后端重定向信号一起发送到 Ftq,进而随同取指请求一起发送到 ICache。其本质是一种 ITLB 异常,因此解释描述和处理方式与 ITLB 相同。
另外,L2 cache 通过 tilelink 总线响应 corrupt 可能是 L2 ECC 错误(d.corrupt),亦可能是无权限访问总线地址空间导致拒绝访问(d.denied)。tilelink 手册规定,当拉高 d.denied 时必须同时拉高 d.corrupt。而这两种情况都需要将取指块标记为 access fault,因此目前在 ICache 中无需区分这两种情况(即无需关注 d.denied,其可能被 chisel 自动优化掉而导致 verilog 中看不到)。
这些异常间存在优先级:backend 异常 > ITLB 异常 > PMP 异常 > MissUnit 异常。这是自然的: 1. 当出现 backend 异常时,发送到前端的 vaddr 不完整且不合法,故 ITLB 地址翻译过程无意义,检查出的异常无效; 2. 当出现 ITLB 异常时,翻译得到的 paddr 无效,故 PMP 检查过程无意义,检查出的异常无效; 3. 当出现 PMP 异常时,paddr 无权限访问,不会发送(预)取指请求,故不会从 MissUnit 得到响应。
而对于 backend 的三种异常、ITLB 的三种异常,由 backend 和 ITLB 内部进行有优先级的选择,保证同时至多只有一种拉高。
此外,一些机制还会引发一些特殊情况,在旧版文档/代码中也称为异常,但其实际上并不引发 RISC-V 手册定义的 exception,为了避免混淆,此后将称为特殊情况:
| 来源 | 特殊情况 | 描述 | 处理 |
|---|---|---|---|
| PMP | mmio | 物理地址为 mmio 空间 | 禁止取指,标记取指块为 mmio,由 IFU 进行非推测性取指 |
| ITLB | pbmt.NC | 页属性为不可缓存、幂等 | 禁止取指,由 IFU 进行推测性取指 |
| ITLB | pbmt.IO | 页属性为不可缓存、非幂等 | 同 pmp mmio |
| MainPipe | ECC error | 主流水检查发现 MetaArray/DataArray ECC 错误 | 见ECC 一节,旧版同 ITLB af,新版做自动重取 |
DataArray 分 bank 的低功耗设计
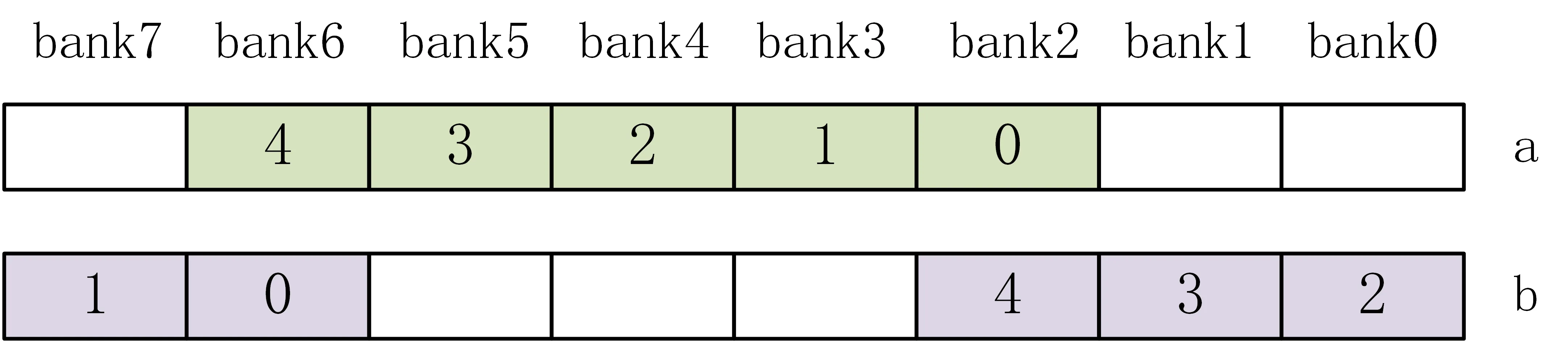
目前,ICache 中每个 cacheline 分为 8 个 bank,bank0-7。一个取指块需要 34B 指令数据,故一次访问连续的 5 个 bank。存在两种情况:
- 这 5 个 bank 位于单个 cacheline 中(起始地址位于 bank0-3)。假设起始地址位于 bank2,则所需数据位于 bank2-6。如下图 a。
- 跨 cacheline(起始地址位于 bank4-7)。假设起始地址位于 bank6,则数据位于 cacheline0 的 bank6-7、cacheline1 的 bank0-2。有些类似于环形缓冲区。如下图 b。
当从 SRAM 或 MSHR 中获取 cacheline 时,根据地址将数据放入对应的 bank。
由于每次访问只需要 5 个 bank 的数据,因此 ICache 到 IFU 的端口实际上只需要一个 64B 的端口,将两个 cacheline 各自的 bank 选择出来并拼接在一起返回给 IFU(在 DataArray 模块内完成);IFU 将这一个 64B 的数据复制一份拼接在一起,即可直接根据取指块起始地址选择出取指块的数据。不跨行/跨行两种情况的示意图如下:
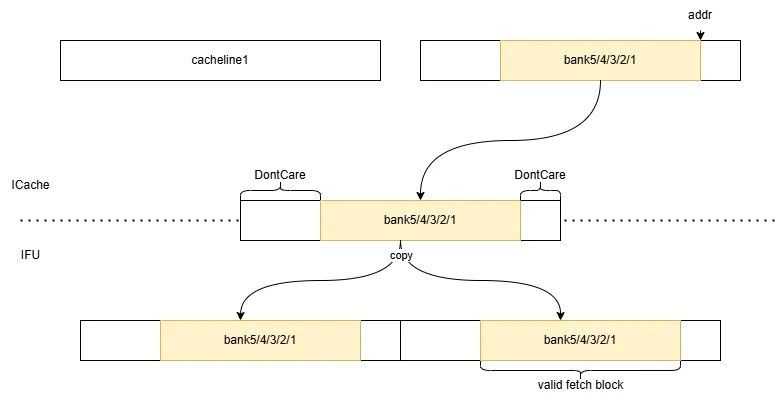
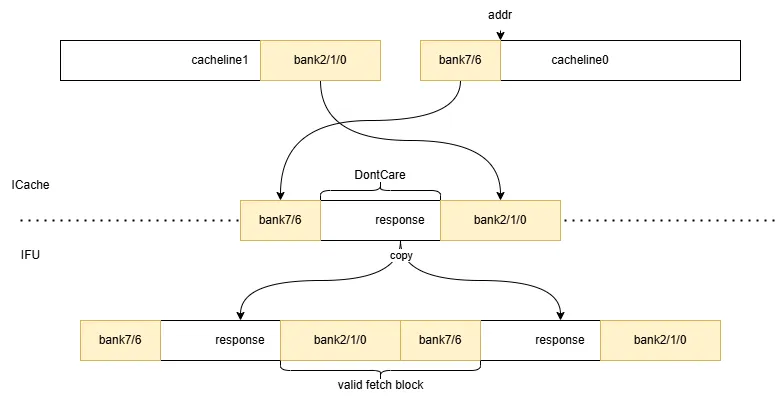
亦可参考 IFU.scala 中的注释。
冲刷
在后端/IFU 重定向、BPU 重定向、fence.i 指令执行时,需要视情况对 ICache 内的存储结构和流水级进行冲刷。可能的冲刷目标/动作有:
- MainPipe、IPrefetchPipe 所有流水级
- 冲刷时直接将
s0/1/2_valid置为false.B即可
- 冲刷时直接将
- MetaArray 中的 valid
- 冲刷时直接将
valid置为false.B即可 tag、code不需要冲刷,因为它们的有效性由valid控制- DataArray 中的数据不需要冲刷,因为它们的有效性由 MetaArray 中的
valid控制
- 冲刷时直接将
- WayLookup
- 读写指针复位
gpf_entry.valid置为false.B
- MissUnit 中所有 MSHR
- 若 MSHR 尚未向总线发出请求,直接置无效(
valid === false.B) - 若 MSHR 已经向总线发出请求,记录待冲刷(flush === true.B或fencei === true.B),等到 d 通道收到 grant 响应时再置无效,同时不把 grant 的数据回复给 MainPipe/PrefetchPipe,也不写入 SRAM - 需要留意,当 d 通道收到 grant 响应的同时收到冲刷(io.flush === true.B或io.fencei === true.B)时,MissUnit 同样不写入 SRAM,但会将数据回复给 MainPipe/PrefetchPipe,避免将端口的延时引入响应逻辑中,此时 MainPipe/PrefetchPipe 也同步收到了冲刷请求,因此会将数据丢弃
- 若 MSHR 尚未向总线发出请求,直接置无效(
每种冲刷原因需要执行的冲刷目标:
| 冲刷原因 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 后端/IFU 重定向 | Y | Y | Y | |
| BPU 重定向 | Y2 | |||
fence.i |
Y3 | Y | Y3 | Y |
ICache 进行冲刷时不接收取指/预取请求(io.req.ready === false.B)
对 ITLB 的冲刷
ITLB 的冲刷比较特殊,其缓存的页表项仅需要在执行 sfence.vma 指令时冲刷,而这条冲刷通路由后端负责,因此前端/ICache 一般不需要管理 ITLB 的冲刷。只有一个特例:目前 ITLB 为了节省资源,不会存储 gpaddr,而是在 gpf 发生时去 L2TLB 重取,重取状态由一个 gpf 缓存控制,这要求 ICache 在收到 ITLB.resp.excp.gpf_instr 时保证下面两个条件之一:
- 重发相同的
ITLB.req.vaddr,直到ITLB.resp.miss拉低(此时gpf、gpaddr均有效,正常发往后端处理即可),ITLB 此时会冲刷gpf缓存。 - 给
ITLB.flushPipe,ITLB 在收到该信号时会冲刷gpf缓存。
若 ITLB 的 gpf 缓存未被冲刷,就收到了不同 ITLB.req.vaddr 的请求,且再次发生 gpf,将导致核卡死。
因此,每当冲刷 IPrefetchPipe 的 s1 流水级时,无论冲刷原因为何,都需要同步冲刷 ITLB 的 gpf 缓存(即拉高 ITLB.flushPipe)。
ECC
首先需要指出,ICache 在默认参数下使用 parity code,其仅具备 1 bit 错误检测能力,不具备错误恢复能力,严格意义上不能算是 ECC(Error Correction Code)。但一方面,其可以配置为使用 secded code;另一方面,我们在代码中大量使用 ECC 来命名错误检测与错误恢复相关的功能(ecc_error、ecc_inject等)。因此本文档仍将使用 ECC 一词来指代错误检测、错误恢复、错误注入相关功能以保证与代码的一致性。
ICache 支持错误检测、错误恢复、错误注入功能,是 RAS4 能力的一部分,可以参考 RISC-V RERI5 手册,由 CtrlUnit 进行控制。
错误检测
在 MissUnit 向 MetaArray 和 DataArray 重填数据时,会计算 meta 和 data 的校验码,前者和 meta 一起存储在 Meta SRAM 中,后者存储在单独的 Data Code SRAM 中。
当取指请求读取 SRAM 时,会同步读取出校验码,在 MainPipe 的 s1/s2 流水级中分别对 meta/data 进行校验。软件可以通过向 CSR 中相应位置写入特定的值来使能/关闭这一功能,在 6-12 月的版本中为自定义 CSR sfetchctl,后续换成 mmio-mapped CSR,详见 CtrlUnit 文档。
在校验码设计方面,ICache 使用的校验码可由参数控制,默认使用的是 parity code,即校验码为对数据做规约异或 \(code = \oplus data\)。检查时只需将校验码和数据一起做规约异或 \(error = (\oplus data) \oplus code\),结果为 1 则发生错误,反之认为没有错误(可能出现偶数个错误,但此处检查不出来)。
在 #4044 以后的版本中,ICache 支持错误注入,这要求 ICache 支持向 MetaArray/DataArray 写入错误的校验码。因此实现了一个poison位,当其拉高时,翻转写入的 code,即 \(code = (\oplus data) \oplus poison\)。
为了减少检查不出的情况,目前将 data 划分成 DataCodeUnit(默认为 64bit)的单元分别进行奇偶校验,因此对每个 64B 的缓存行,总计会计算 \(8(data) + 1(meta) = 9\) 个校验码。
当 MainPipe 的 s1/s2 流水级检查到错误时,会进行以下处理:
在 6 月至 11 月的版本中:
- 错误处理:引起 access fault 异常,由软件处理。
- 错误报告:向 BEU 报告错误,后者会引起中断向软件报告错误。
- 取消请求:当 MetaArray 被检查出错误时,其读出的 ptag 不可靠,进而对 hit 与否的判断不可靠,因此无论是否 hit 都不向 L2 Cache 发送请求,而是直接将异常传递到 IFU、进而传递到后端处理。
在后续版本(#3899 后)实现了错误自动恢复机制,故只需进行以下处理:
- 错误处理:从 L2 Cache 重新取指,见下节。
- 错误报告:同上向 BEU 报告错误。
错误自动恢复
注意到,ICache 与 DCache 不同,是只读的,因此其数据必然不是 dirty 的,这意味着我们总是可以从下级存储结构(L2/3 Cache、memory)中重新获取正确的数据。因此,ICache 可以通过向 L2 Cache 重新发起 miss 请求来实现错误自动恢复。
实现重取功能本身只需要复用现有的 miss 取指路径,走 MainPipe -> MissUnit -> MSHR --tilelink-> L2 Cache 的请求路径。MissUnit 向 SRAM 重填数据时会自然地计算新的校验码并存储,因此在重取后会回到无错误的状态而不需要额外的处理。
6-11 月和后续代码行为差异的伪代码示意如下:
- exception = itlb_exception || pmp_exception || ecc_error
+ exception = itlb_exception || pmp_exception
- should_fetch = !hit && !exception
+ should_fetch = (!hit || ecc_error) && !exception
需要留意的是:为了避免重取后出现 multi-hit(即,同一个 set 内存在多个 way 的 ptag 相同),需要在重取前将 metaArray 对应位置的 valid 清空:
- 若 MetaArray 错误:meta 保存的 ptag 本身可能出错,命中结果(one-hot 的 waymask)不可靠,“对应位置”指该 set 的所有 way
- 若 DataArray 错误:命中结果可靠,“对应位置”指该 set 中 waymask 拉高的那一 way
错误注入
根据 RERI 手册5的说明,为了使软件能够测试 ECC 功能,进而更好地判断硬件功能是否正常,需要提供错误注入功能,即主动地触发 ECC 错误。
ICache 的错误注入功能由 CtrlUnit 控制,通过向 mmio-mapped CSR 中相应位置写入特定的值来触发。详见 CtrlUnit 文档。
目前 ICache 支持:
- 向特定 paddr 注入,当请求注入的 paddr 未命中时,注入失败
- 向 MetaArray 或 DataArray 注入
- 当 ECC 校验功能本身未使能时,注入失败
软件注入流程示意如下:
inject_target:
# maybe do something
ret
test:
la t0, $BASE_ADDR # 载入 mmio-mapped CSR 基地址
la t1, inject_target # 载入注入目标地址
jalr ra, 0(t1) # 跳转到注入目标以保证其加载到 ICache
sd t1, 8(t0) # 向 CSR 写入注入目标地址
la t2, ($TARGET << 2 | 1 << 1 | 1 << 0) # 设置注入目标、注入使能、校验使能
sd t1, 0(t0) # 向 CSR 写入注入请求
loop:
ld t1, 0(t0) # 读取 CSR
andi t1, t1, (0b11 << (4+1)) # 读取注入状态
beqz t1, loop # 如果注入未完成,继续等待
addi t1, t1, -1
bnez t1, error # 如果注入失败,跳转到错误处理
jalr ra, 0(t1) # 注入成功,跳转到注入目标地址以触发错误
j finish # 结束
error:
# handle error
finish:
# finish
我们编写了一个测试用例,见此仓库,其测试了如下情况:
- 正常注入 MetaArray
- 正常注入 DataArray
- 注入无效的目标
- 注入但 ECC 校验未使能
- 注入未命中的地址
- 尝试写入只读的 CSR 域
参考文献
- Glenn Reinman, Brad Calder, and Todd Austin. "Fetch directed instruction prefetching." 32nd Annual ACM/IEEE International Symposium on Microarchitecture (MICRO). 1999.
-
BPU 精确预测器(BPU s2/s3 给出结果)可能覆盖简单预测器(BPU s0 给出结果)的预测,显然其重定向请求最晚在预取请求的 1- 2 拍之后就到达 ICache,因此仅需要:
BPU s2 redirect:冲刷 IPrefetchPipe s0
BPU s3 redirect:冲刷 IPrefetchPipe s0/1
当 IPrefetchPipe 的对应流水级中的请求来自于软件预取时
isSoftPrefetch === true.B,不需要进行冲刷当 IprefetchPipe 的对应流水级中的请求来自于硬件预取,但
ftqIdx与冲刷请求不匹配时,不需要进行冲刷 ↩ -
fence.i在逻辑上需要冲刷 MainPipe 和 IPrefetchPipe(因为此时流水级中的数据可能无效),但实际上io.fencei拉高必然伴随一个后端重定向,因此目前的实现中没有冲刷 MainPipe 和 IPrefetchPipe 的必要。 ↩↩ -
此 RAS(Reliability, Availability, and Serviceability)非彼 RAS(Return Address Stack)。 ↩
-
RERI(RAS Error-record Register Interface),参考 RISC-V RERI 手册。 ↩↩