昆明湖 IFU 模块文档
- 版本:V2R2
- 状态:OK
- 日期:2025/01/03
- commit:7d889d887f665295eec9cdb987e037e008f875a6
术语说明
| 缩写 | 全称 | 描述 |
|---|---|---|
| CRU | Clock Reset Unit | 时钟复位单元 |
| RVC | RISC-V Compressed Instructions | RISC-V 手册"C"扩展规定的 16 位长度压缩指令 |
| RVI | RISC-V Integer Instructions | RISC-V 手册规定的 32 位基本整型指令 |
| IFU | Instruction Fetch Unit | 取指令单元 |
| FTQ | Fetch Target Queue | 取指目标队列 |
| PreDecode | Predecoder Module | 预译码器 |
| PredChecker | Prediction Check Module | 分支预测结果检查器 |
| ICache | L1 Instruction Cache | 一级指令缓存 |
| IBuffer | Instruction Buffer | 指令缓冲 |
| CFI | Control Flow Instruction | 控制流指令 |
| PC | Program Counter | 程序计数器 |
| ITLB | Instruction Translation Lookaside Buffer | 指令地址转译后备缓冲器 |
| InstrUncache | Instruction Ucache Module | 指令 MMIO 取指处理单元 |
子模块列表
| 子模块 | 描述 |
|---|---|
| PreDecoder | 预译码模块 |
| InstrUncache | 指令 MMIO 取指处理单元 |
功能描述
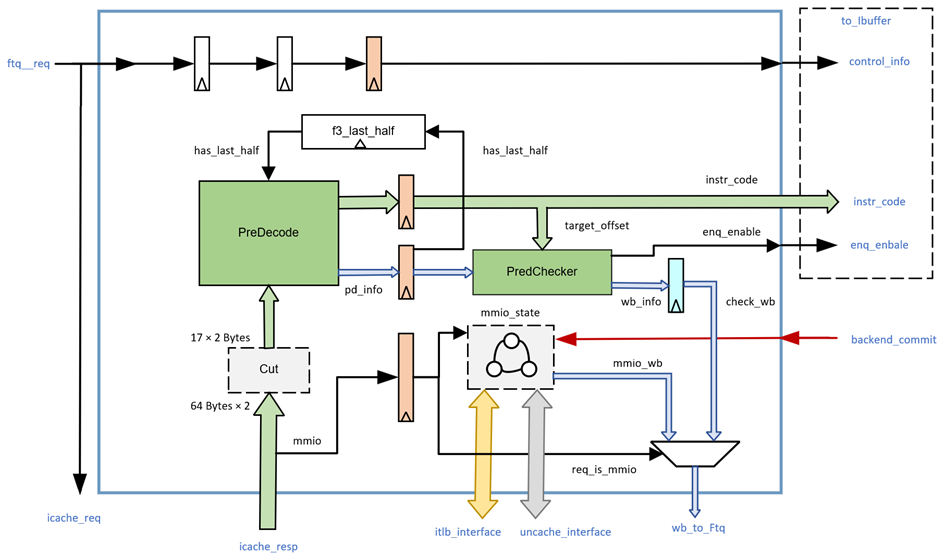
FTQ 将预测块请求分别发送到 ICache 和 IFU 模块,IFU 等到来自 ICache 返回至多两个缓存行的指令码后,进行切分产生取指令请求范围限定的初始指令码,并送到预译码器进行预译码下一拍根据预译码信息修正有效指令范围,同时进行指令码扩展并将指令码及其他信息发送给 IBuffer 模块。当 ICache 查询地址属性发现是 MMIO 地址空间时,IFU 需要将地址发送给 MMIO 处理单元取指令,这个时候处理器进入多周期顺序执行模式,IFU 阻塞流水线直到收到来自 ROB 的提交信号时,IFU 才允许下一个取指令请求的进行,同时 IFU 需要对跨页的 MMIO 地址空间 32 位指令做特殊处理(重发机制)。
接受 FTQ 取指令请求
IFU 接收来自 FTQ 以预测块为单位的取指令请求,包括预测块起始地址、起始地址所在 cacheline 的下一个 cacheline 开始地址、下一个预测块的起始地址、该预测块在 FTQ 里的队列指针、该预测块有无 taken 的 CFI 指令和该 taken 的 CFI 指令在预测块里的位置以及请求控制信号(请求是否有效和 IFU 是否 ready)。每个预测块最多包含 32 字节指令码,最多为 16 条指令。
双 cacheline 取指
当且仅当预测块的取指地址在 cacheline 的后半段时,为了满足一个预测块最多 34 字节的需要,IFU 将从 ICache 中取回连续的两个 cacheline,分别产生例外信息(page fault 和 access fault),如后述特性 3 进行切分。
在 2024/06 以后,ICache 实现了低功耗设计,会在内部进行数据的选择和拼接,因此 IFU 不需要关心两个 cacheline 的数据如何拼接和选择,只需要简单地将 ICache 返回的数据复制一份拼接在一起,即可进行切分。请参考 ICache 文档。
亦可参考 IFU.scala 中的注释。
指令切分产生初始指令码
下一流水级(F1 级),计算出预测块内每 2 字节的 PC 和其他一些信息,然后进入 F2 流水级等待 ICache 返回指令码,在 F2 级需要检查 ICache 返回的指令码和本流水级是否匹配(因为 IFU 的流水级会被冲刷而 ICache 不会)。然后根据 ICache 返回的缓存行例外信息产生每条指令的例外信息(page fault 和 access fault),同时根据 FTQ 的 taken 信息计算一个跳转时指令有效范围 jump_range(即此预测块从起始地址到第一条跳转地址的指令范围)和无跳转时指令有效范围 ftr_range(即此预测块从起始地址到下一个预测块的起始地址)。为了时序相关的考虑,ICache 的两个端口分别会返回 miss 和 hit 时候两个来源的缓存行,这个四个缓存行需要产生 4 种组合(0 号端口的两个和 1 号端口的两个)同时进行预译码。F2 会并行对返回的 64 字节的数据中(其中 40 字节有效数据)根据预测块的起始地址选择出 17×2 字节的初始指令码,并送到 4 个 PreDecode 模块进行预译码。
产生预译码信息
PreDecode 模块接受 F2 切分后的 17 个 2 字节初始指令码,一方面将这些初始指令码根据译码表进行预译码得到预译码信息,包括该指令是否是有效指令的开始、是否是 RVC 指令、是否是 CFI 指令、CFI 指令类型(branch/jal/jalr/call/ret)、CFI 指令的目标地址计算偏移等。输出的预译码信息中 brType 域的编码如下:
表 1.2 CFI 指令类型编码
| CFI 指令类型 | 类型编码( brType ) |
|---|---|
| 非 CFI 指令 | 00 |
| branch 指令 | 01 |
| jal 指令 | 10 |
| jalr 指令 | 11 |
生成指令码和指令码扩展
产生预译码信息的同时将初始指令进行 4 字节组合(从起始地址开始,2 字节做地址递增,地址开始的 4 字节作为一条 32 位初始指令码)产生每条指令的指令码
在产生指令码和预译码信息的下一拍(F3)将 16 条指令的指令码分别送到 16 个指令扩展器进行 32 位指令扩展(RVC 指令根据手册的规定进行扩充,RVI 保留指令码不变)。
分支预测 overriding 冲刷流水线
当 FTQ 内未缓存足够预测块时,IFU 可能直接使用简单分支预测器提供的预测地址进行取指,这种情况下,当精确预测器发现简单预测器错误时,需要通知 IFU 取消正在进行的取指请求。具体而言,当 BPU 的 S2 流水级发现错误时,需要冲刷 IFU 的 F0 流水级;当 BPU 的 S3 流水级发现错误时,需要冲刷 IFU 的 F0/F1 流水级(BPU 的简单预测器在 S1 给出结果,最晚在 S3 进行 overriding,因此 IFU 的 F2/F3 流水级一定是最好的预测,不需要冲刷;类似地,不存在 BPU S2 到 IFU F1 的冲刷)。
IFU 在收到 BPU 发送的冲刷请求时,会将 F0、F1 流水级上取指请求的指针与 BPU 发送的冲刷请求的指针进行比较,若冲刷的指针在取指的指针之前,说明当前取指请求在错误的执行路径上,需要进行流水线冲刷;反之,IFU 可以忽略 BPU 发送的这一冲刷请求。
分支预测错误提前检查
为了减少一些比较容易识别的分支预测错误的冲刷,IFU 在 F3 流水级使用 F2 产生的预译码信息做前端的分支预测错误检查。预译码信息首先送到 PredChecker 模块,根据其中的 CFI 指令类型检查 jal 类型错误、ret 类型错误、无效指令预测错误、非 CFI 指令预测错误,同时根据指令码计算 16 个转移目标地址,和预测的目标地址进行比对,检查转移目标地址错误,PredChecker 将纠正 jal 类型错误 、ret 错误的预测结果以及 jalr 错误的预测结果,并重新产生指令有效范围向量 fixedRange(为 1 表示该条指令在预测块内),fixedRange 在 jump_range 和 ftr_range 的基础上根据 jal 和 ret 的检查结果,把范围缩小到起始地址到没有检测出来的 jal 或者 ret 指令。下面是 PredChecker 模块对分支预测检查的错误类型:
- jal 类型错误:预测块的范围内有 jal 指令,但是预测器没有对这条指令预测跳转或预测块预测跳转位置在其之后;
- jalr 类型错误:预测块的范围内有 jalr 指令,但是预测器没有对这条指令预测跳转或预测块预测跳转位置在其之后;
- ret 类型错误:预测块的范围内有 ret 指令,但是预测器没有对这条指令预测跳转或预测块预测跳转位置在其之后;
- 无效指令预测错误:预测器对一条无效的指令(不在预测块范围/是一条 32 位指令中间)进行了预测;
- 非 CFI 指令预测错误:预测器对一条有效但是不是 CFI 的指令进行了预测;
- 转移目标地址错误:预测器给出的转移目标地址不正确。
前端重定向
如果 F3 分支预测的检查结果显示这个预测块有特性 7 里所述的 5 种预测错误,那么 IFU 将在下一拍产生一个前端重定向,将除 F3 之外的流水级冲刷。FTQ 以及预测器的冲刷将由 IFU 写会 FTQ 后由 FTQ 完成。
将指令码和前端指令信息送到 IBuffer
F3 流水级最终得到经过扩展的 32 位指令码,以及 16 条指令中每条指令的例外信息、预译码信息、FTQ 指针、其他后端需要的信息(比如经过折叠的 PC)等。IFU 除了常规的 valid-ready 控制信号外,还会给 IBuffer 两个特殊的信号:一个是 16 位的 io_toIbuffer_bits_valid,标识预测块里有效的指令(为 1 说明是一条指令的开始,为 0 则是说明是一条指令的中间)。另一个是 16 位的 io_toIbuffer_bits_enqEnable,这个在 io_toIbuffer_bits_valid 的基础上与上了被修正过的预测块的指令范围 fixedRange。enqEnable 为 1 表示这个 2 字节指令码是一条指令的开始且在预测块表示的指令范围内。
指令信息和误预测信息写回 FTQ
在 F3 的下一级 WB 级,IFU 将指令 PC、预译码信息、错误预测指令的位置、正确的跳转地址以及预测块的正确指令范围等信息写回 FTQ,同时传递该预测块的 FTQ 指针用以区分不同请求。
跨预测块 32 位指令处理
因为预测块的长度有限制,因此存在一条 RVI 指令前后两字节分别在两个预测块的情况。IFU 首先在第一个预测块里检查最后 2 字节是不是一条 RVI 指令的开始,如果是并且该预测块没有跳转,那么就设置一个标识寄存器 f3_lastHalf_valid,告诉接下来的预测块含有后半条指令。在 F2 预译码时,会产生两种不同的指令有效向量:
- 预测块起始地址开始即为一条指令的开始,以这种方式根据后续指令是 RVC 还是 RVI 产生指令有效向量
- 预测块起始地址是一条 RVI 指令的中间,以起始地址+2 位一条指令的开始产生有效向量
在 F3,根据是否有跨预测块 RVI 标识来决定选用哪种作为最终的指令有效向量,如果 f3_lastHalf_valid 为高则选择后一种(即这个预测块第一个 2 字节不是指令的开始)。如前面特性 2 所述,当且仅当起始地址在后半 cacheline,就会向 ICache 取两个 cacheline,因此即使这条跨预测块的 RVI 指令也跨 cacheline,每个预测块都能拿到它的完整指令码。IFU 所做的处理只是把这条指令算在第一个预测块里,而把第二个预测块的起始地址位置的 2 字节通过改变指令有效向量来无效掉。
MMIO 取指令
在处理器上电解复位时,由于内存初始化还未完成,因此处理器需要从 flash 存储里取指令运行,这种情况下需要 IFU 向 MMIO 总线发送宽度为 64 位的请求从 flash 地址空间取指令执行。同时 IFU 禁止对 MMIO 总线的推测执行,即 IFU 需要等到每一条指令执行完成得到准确的下一条指令地址之后才继续向总线发送请求。
处理器上电解复位后,从 0x10000000 地址开始取指令,ICache 经过 ITLB 地址翻译得到物理地址,物理地址经过 PMP 查询是否属于 MMIO 空间,并将检查结果返回到 IFU F2 流水级(见 ICache 文档)。如果是 MMIO 地址空间的取指令请求,IFU 将请求阻塞在 F3 并由一个状态机控制 MMIO 取指令,由下图所示:

- 状态机默认在
m_idle状态,若 F3 流水级是 MMIO 取指令请求,且此前没有发生异常,状态机进入m_waitLastCmt状态。 - (
m_waitLastCmt)IFU 通过 mmioCommitRead 端口到 FTQ 查询,IF3 预测块之前的指令是否都已提交,如果没有提交则阻塞等待前面的指令都提交完1。 - (
m_sendReq)将请求发送到 InstrUncache 模块,向 MMIO 总线发送请求。 - (
m_waitResp)InstrUncache 模块返回后根据 pc 从 64 位数据中截取指令码。 - 若 pc 低位为
3'b110,由于 MMIO 总线的带宽限制为 8B 且只能访问对齐的区域,本次请求的高 2B 将不是有效的数据。若返回的指令数据表明指令不是 RVC 指令,则这种情况需要对 pc+2 的位置(即对齐到下一个 8B 的位置)进行重发才能取回完整的 4B 指令码。 - 重发前,需要重新对 pc+2 进行 ITLB 地址翻译和 PMP 检查(因为可能跨页)(
m_sendTLB、m_TLBResp、m_sendPMP),若 ITLB 或 PMP 出现异常(access fault、page fault、guest page fault)、或检查发现 pc+2 的位置不在 MMIO 地址空间,则直接将异常信息发送到后端,不进行取指。 - 若无异常,(
m_resendReq、m_waitResendResp)类似 2/3 两步向 InstrUncache 发出请求并收到指令码。 - 当 IFU 寄存了完整的指令码,或出错(重发时的ITLB/PMP出错,或 Uncache 模块 tilelink 总线返回 corrupt)时,(
m_waitCommit)即可将指令数据和异常信息发送到 IBuffer。需要注意,MMIO 取指令每次只能非推测性地向总线发起一条指令的取指请求,因此也只能向 IBuffer 发送一条指令数据。并等待指令提交。 - 若这条指令是 CFI 指令,由后端发送向 FTQ 发起冲刷。
- 若是顺序指令,则由 IFU 复用前端重定向通路刷新流水线,同时复用 FTQ 写回机制,把它当作一条错误预测的指令进行冲刷,重定向到该指令地址 +2 或者 +4(根据这条指令是 RVI 还是 RVC 选择)。这一机制保证了 MMIO 每次只取入一条指令。
- 提交后,(
m_commited)状态机复位到m_idle并清空各类寄存器。
除了上电时,debug 扩展、Svpbmt 扩展可能也会使处理器在运行的任意时刻跳到一块 MMIO 地址空间取指令,请参考 RISC-V 手册。对这些情况中 MMIO 取指的处理是相同的。
Trigger 实现对于 PC 的硬件断点功能
在 IFU 的 FrontendTrigger 模块里共 4 个 Trigger,编号为 0-3,每个 Trigger 的配置信息(断点类型、匹配地址等)保存在 tdata 寄存器中。
当软件向 CSR 寄存器 tselect、tdata1/2 写入特定的值时,CSR 会向 IFU 发送 tUpdate 请求,更新 FrontendTrigger 内的 tdata 寄存器中的配置信息。目前前端的 Trigger 仅可以配置成 PC 断点(mcontrol.select 寄存器为 0;当 mcontrol.select=1 时,该 Trigger 将永远不会命中,且不会产生异常)。
在取指时,IFU 的 F3 流水级会向 FrontendTrigger 模块发起查询并在同一周期得到结果。后者会对取指块内每一条指令在每一个 Trigger 上做检查,当不处于 debug 模式时,指令的 PC 和 tdata2 寄存器内容的关系满足 mcontrol.match 位所指示的关系(香山支持 mcontrol.match 位为 0、2、3,对应等于、大于、小于)时,该指令会被标记为 Trigger 命中,随着执行在后端产生断点异常,进入 M-Mode 或调试模式。前端的 Trigger 支持 Chain 功能。当它们对应的 mcontrol.chain 位被置时,只有当该 Trigger 和编号在它后面一位的 Trigger 同时命中时,处理器才会产生异常2。
总体设计
整体框图和流水级

接口时序
FTQ 请求接口时序示例
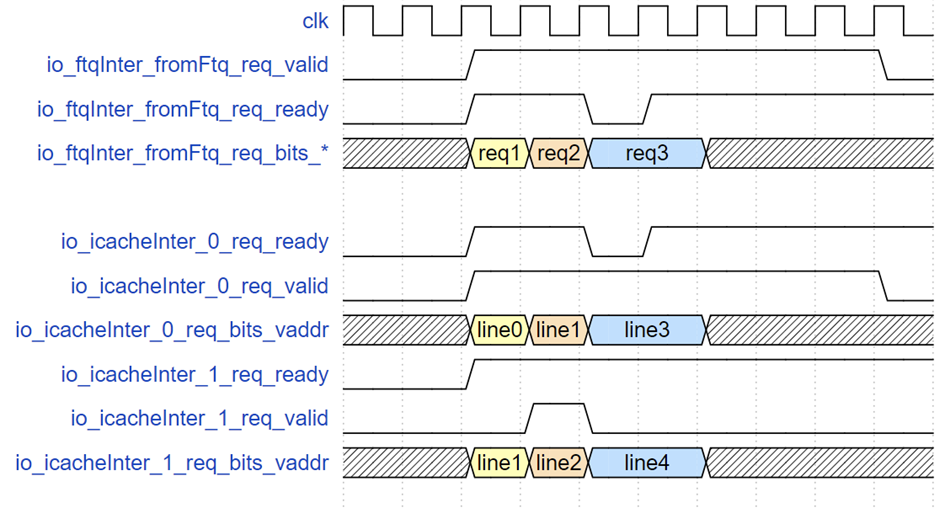
上图示意了三个 FTQ 请求的示例,req1 只请求缓存行 line0,紧接着 req2 请求 line1 和 line2,当到 req3 时,由于指令缓存 SRAM 写优先,此时指令缓存的读请求 ready 被指低,req3 请求的 valid 和地址保持直到请求被接收。
ICache 返回接口以及到 Ibuffer 和写回 FTQ 接口时序示例
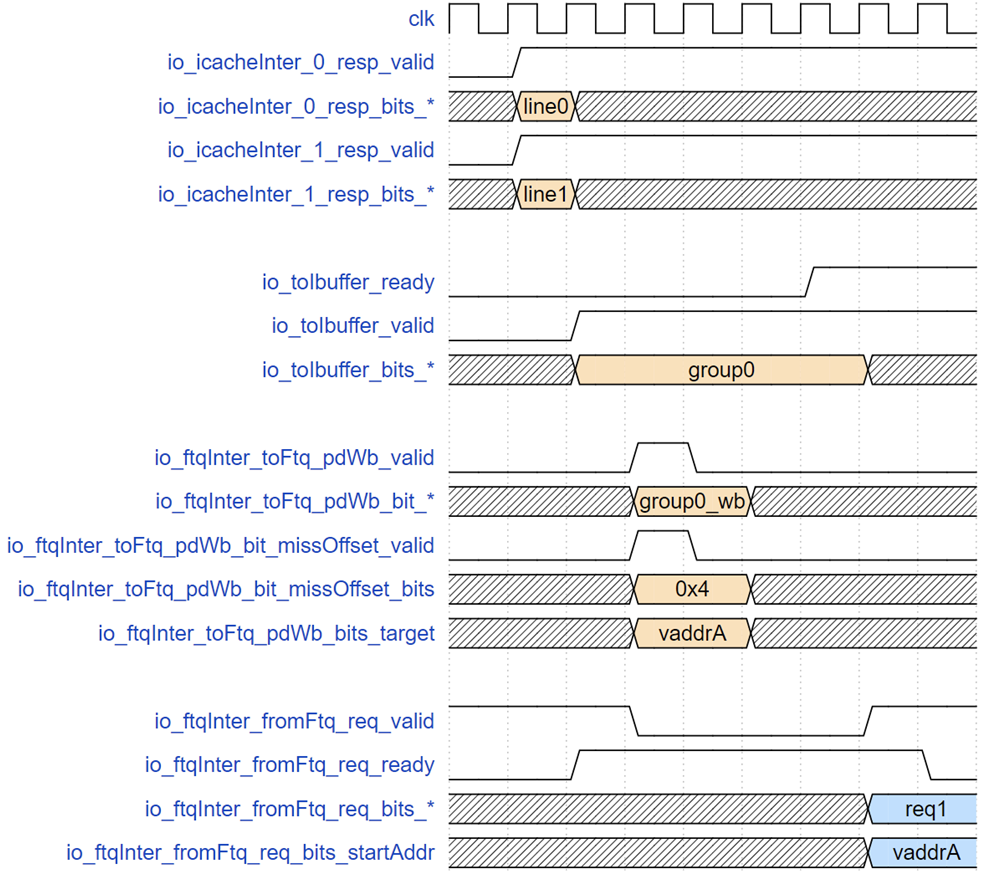
上图展示了指令缓存返回数据到 IFU 发现误预测直到 FTQ 发送正确地址的时序,group0 对应的请求在 f2 阶段了两个缓存行 line0 和 line1,下一拍 IFU 做误预测检查并同时把指令给 Ibuffer,但此时后端流水线阻塞导致 Ibuffer 满,Ibuffer 接收端的 ready 置低,goup0 相关信号保持直到请求被 Ibuffer 接收。但是 IFU 到 FTQ 的写回在 tio_toIbuffer_valid 有效的下一拍就拉高,因为此时请求已经无阻塞地进入 wb 阶段,这个阶段锁存的了 PredChecker 的检查结果,报告 group0 第 4(从 0 开始)个 2 字节位置对应的指令发生了错误预测,应该重定向到 vaddrA,之后经过 4 拍(冲刷和重新走预测器流水线),FTQ 重新发送给 IFU 以 vaddrA 为起始地址的预测块。
MMIO 请求接口时序示例

上图展示了一个 MMIO 请求 req1 的取指令时序,首先 ICache 返回的 tlbExcp 信息报告了这是一条 MMIO 空间的指令(其他例外信号必须为低),过两拍 IFU 向 InstrUncache 发送请求,一段时间后收到响应和 32 位指令码,同拍 IFU 将这条指令作为一个预测块发送到 Ibuffer,同时发送对 FTQ 的写回,复用误预测信号端口,重定向地址为紧接着下一条指令的地址。此时 IFU 进入等待指令执行完成。一段时间后 rob_commits 端口报告此条指令执行完成,并且没有后端重定向。则 IFU 重新发起下一条 MMIO 指令的取指令请求。
-
需要特别指出的是,Svpbmt 扩展增加了一个
NC属性,其代表该内存区域是不可缓存的、但是幂等的,这意味着我们可以对NC的区域进行推测执行,也就是不需要“等待前面的指令提交”就可以向总线发送取指请求,表现为状态机跳过等待状态。实现见 #3944。 ↩ -
在过去(riscv-debug-spec-draft,对应 XiangShan 2024.10.05 合入的 PR#3693 前)的版本中,Chain 还需要满足两个 Trigger 的
mcontrol.timing是相同的。而在新版(riscv-debug-spec-v1.0.0)中,mcontrol.timing被移除。目前 XiangShan 的 scala 实现仍保留了这一位,但其值永远为 0 且不可写入,编译生成的 verilog 代码中没有这一位。参考:https://github.com/riscv/riscv-debug-spec/pull/807。 ↩