[XiangShan Biweekly 98] 20260316
Welcome to XiangShan biweekly column! Through this column, we will regularly share the latest development progress of XiangShan. This is the 98th issue of the biweekly report.
Kunminghu V2 has been returned from the fab! We are currently conducting intensive testing, and more information will be disclosed in the future. Stay tuned!
Regarding the recent development progress of XiangShan, the frontend has fixed some performance bugs in BPU, the backend has optimized the timing of some modules, and the memory subsystem continues to undergo refactoring and testing.
Frontend TAGE allocation bug localization and fix
Recently, a team that has been closely following XiangShan's progress reported a performance bug to us. Although they prefer not to disclose their name, their feedback has been invaluable. They observed that when running Kunminghu V3 on FPGA, the performance of V3 was even worse than V2. After a brief investigation, we found that in the libquantum test program, the branch prediction accuracy of V3 significantly decreased as the runtime increased, leading to a drop in IPC.
After receiving this feedback, we immediately started reproducing and locating the issue. ~~Actually, we initially suspected it was an environment issue, since V3 performed well in our slice performance evaluation process, but it turned out that all configurations were correct~~. This phenomenon only became significant after running for about 30 minutes on FPGA, but debugging on FPGA is limited. However, to reproduce it in a simulation environment would require at least a month. Therefore, we ultimately decided to reproduce it on Palladium, which would take about a day.
After a day, we successfully reproduced the issue. The following figure shows the IPC curve over time in the libquantum test program, where we can see a significant drop in IPC after running for a while.
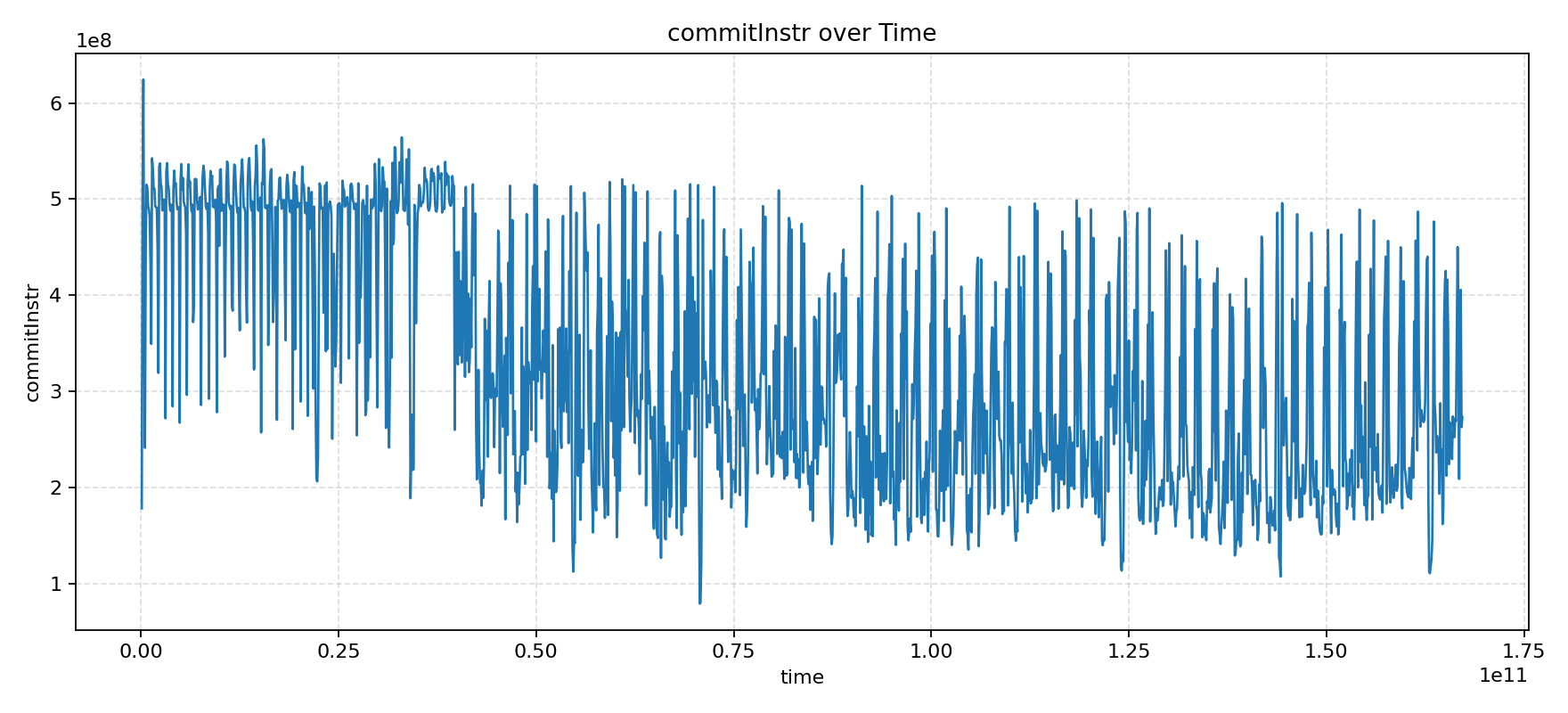
Among the various performance counters, we found that the allocate_failure counter had a trend that was highly correlated with the IPC trend! This counter counts the number of times TAGE entry allocation failed, which should not be so high according to design expectations.
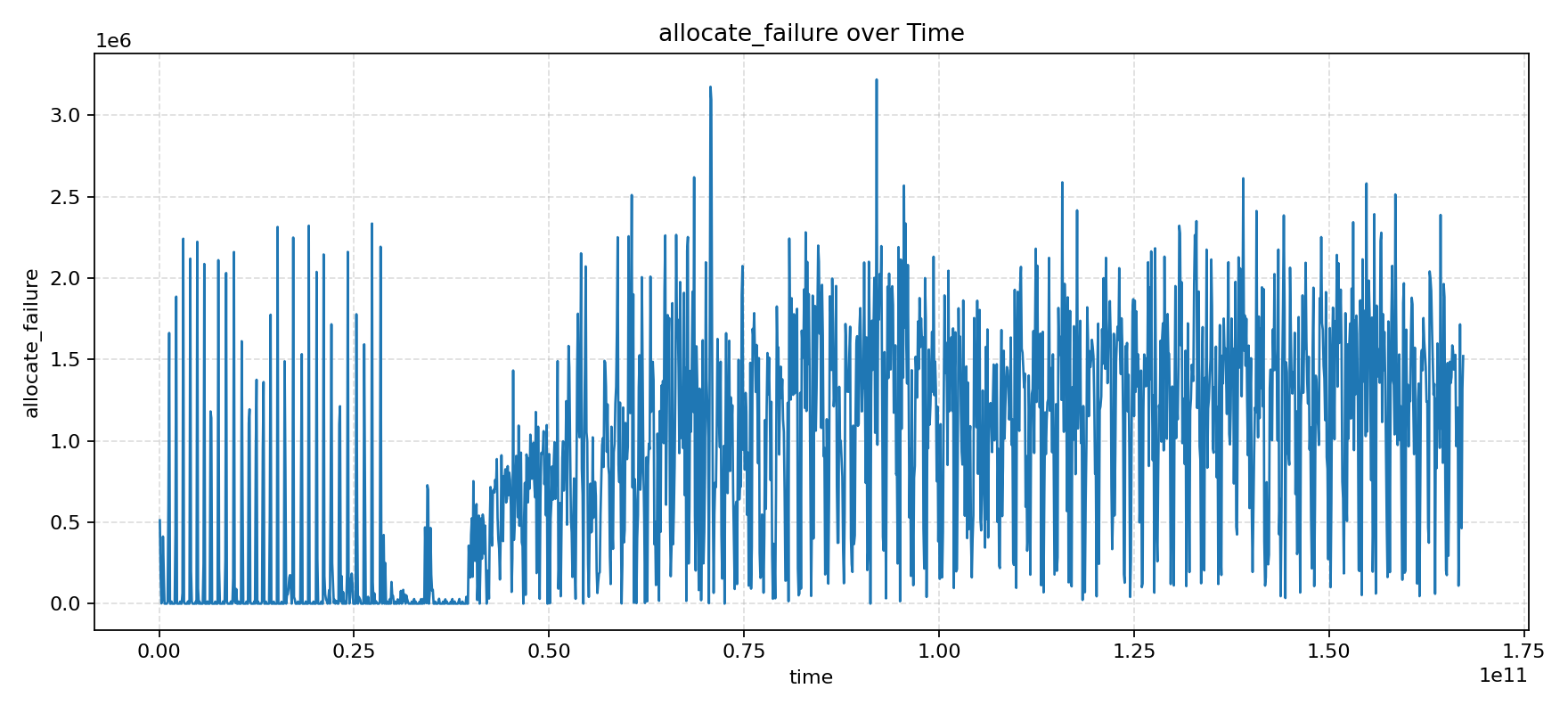
After localization, we found that there was a bug in the TAGE allocation condition, which caused existing entries to not be replaced, leading to new branches not being trained into TAGE. The specific code modification can be referred to in this PR. The IPC and allocate_failure trends after the fix are shown in the following figures.
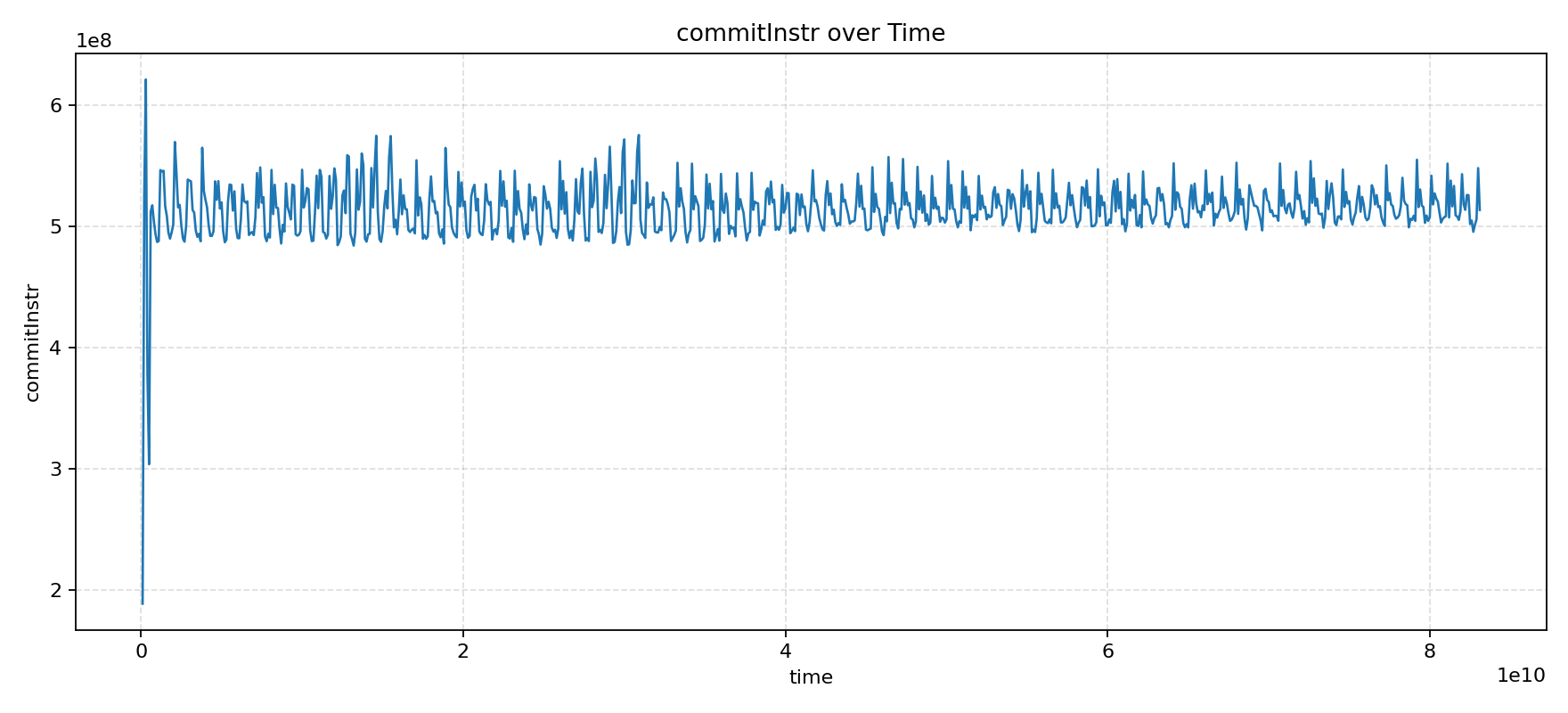
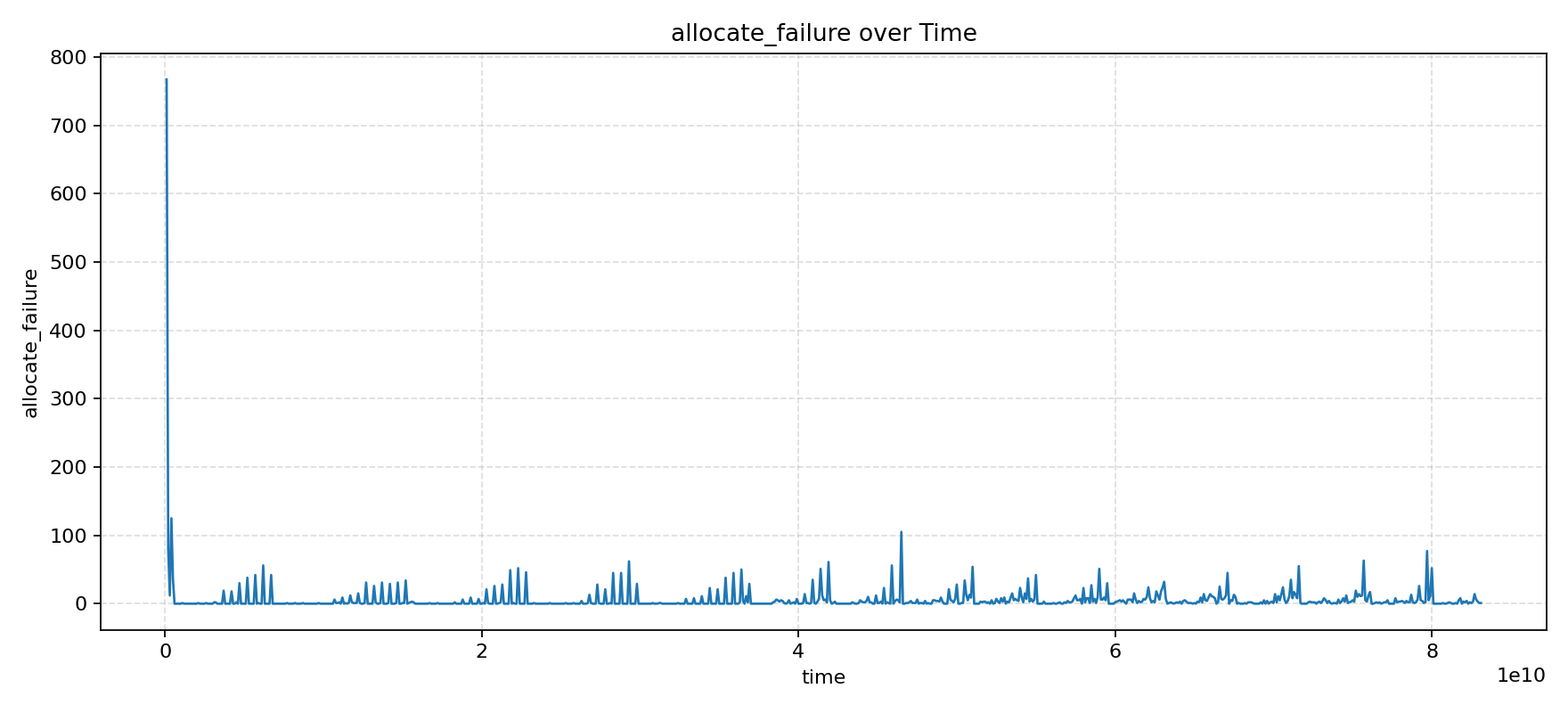
What a beautiful pair of curves! We are very grateful for the continuous attention and active feedback from this mysterious team, and we also welcome more friends who are interested in XiangShan to join us in making XiangShan better and better.
Recent Developments
Frontend
- RTL features
- Support branch-level prediction in UTAGE (#5513)
- Support configurable threshold range (#5632)
- Implement SC IMLI table (#5671)
- Bug fixes
- Fix the issue that saturate counters in MBTB baseTable are not updated when the branch is correctly predicted (#5602)
- Fix history restore logic on s3 override (#5625)
- Fix the bug in TAGE entry allocation logic, which causes the allocation failure rate to soar after running for a while (#5677)
- Timing/Area optimization
- Fix the timing of SC training logic (#5648)
- Code quality
- Fix the issue of incorrect bit width display of cfiPosition in MBTB compile-time logs, which does not affect the actual RTL functionality (#5638)
- Fix MBTB compile-time warning (#5543)
- Debugging tools
- Refactor the performance counters for prediction sources (#5639)
Backend
- RTL new features
- (V2) Add hartIDDmodeWidth to select readable mhartid bits under debug mode (#5627)
- Bug fixes
- Fix the data output of v0 in vldMergeUnit (#5675)
- Timing optimization
- Reduce bju IssueQueue's size, fix IssueQueue's ready timing, fix timing of interrupt selection (#5636)
- Move RatWrapper to Rename to check Rename timing (#5637)
- Code quality
- Improve multiple code quality issues including the Issue section (#5652)
MemBlock and Cache
- RTL new features
- The refactoring and testing of MMU, LoadUnit, StoreQueue, L2, etc. is ongoing
- Increase mmioBridgeSize to 16 for better NC perf (CoupledL2 #475)
- Bug fixes
- Sync V2 changes to V3
- Hold LikelyShared on retried writes in CoupledL2 (CoupledL2 #474)
- Timing fixes
- Generate gpaddr by bitwise-Or instead of adder (#5644)
- Performance fixes refactoring
- Restore performance considering async depth is 4 (CoupledL2 #472)
Performance Evaluation
Processor and SoC parameters are as follows:
| Parameters | Options |
|---|---|
| Commit | 316946d28 |
| Date | 02/11/2026 |
| L1 ICache | 64KB |
| L1 DCache | 64KB |
| L2 Cache | 1MB |
| L3 Cache | 16MB |
| LSU | 3ld2st |
| Bus protocol | CHI |
| Memory latency | DDR4-3200 |
The SPEC CPU2006 scores are as follows:
| SPECint 2006 @ 3GHz | GCC15 | XSCC | GCC12 | SPECfp 2006 @ 3GHz | GCC15 | XSCC | GCC12 |
|---|---|---|---|---|---|---|---|
| 400.perlbench | 47.62 | 46.95 | 43.70 | 410.bwaves | 85.89 | 90.63 | 73.26 |
| 401.bzip2 | 27.11 | 27.84 | 27.45 | 416.gamess | 56.09 | 52.32 | 55.07 |
| 403.gcc | 51.16 | 37.45 | 48.58 | 433.milc | 64.67 | 63.51 | 49.06 |
| 429.mcf | 59.41 | 53.82 | 58.20 | 434.zeusmp | 69.51 | 63.50 | 60.53 |
| 445.gobmk | 35.73 | 36.86 | 37.72 | 435.gromacs | 36.26 | 34.10 | 38.51 |
| 456.hmmer | 52.74 | 62.74 | 42.84 | 436.cactusADM | 75.29 | 86.48 | 53.73 |
| 458.sjeng | 36.53 | 37.26 | 35.81 | 437.leslie3d | 56.49 | 56.52 | 54.49 |
| 462.libquantum | 135.14 | 293.38 | 133.96 | 444.namd | 42.50 | 44.39 | 37.52 |
| 464.h264ref | 62.14 | 70.50 | 62.67 | 447.dealII | 63.78 | 68.00 | 65.01 |
| 471.omnetpp | 40.96 | 39.01 | 43.05 | 450.soplex | 48.91 | 57.65 | 52.82 |
| 473.astar | 30.86 | 29.89 | 30.11 | 453.povray | 72.61 | 66.92 | 61.73 |
| 483.xalancbmk | 74.28 | 83.06 | 79.61 | 454.Calculix | 44.12 | 39.19 | 19.43 |
| GEOMEAN | 49.43 | 52.66 | 48.51 | 459.GemsFDTD | 64.03 | 64.56 | 46.22 |
| 465.tonto | 51.74 | 34.81 | 36.76 | ||||
| 470.lbm | 126.79 | 132.72 | 105.02 | ||||
| 481.wrf | 55.19 | 41.29 | 48.79 | ||||
| 482.sphinx3 | 58.53 | 60.81 | 55.06 | ||||
| GEOMEAN | 60.46 | 58.46 | 50.81 |
Compilation parameters are as follows:
| Parameters | GCC12 | GCC15 | XSCC |
|---|---|---|---|
| Compiler | gcc12 | gcc15 | xscc |
| Optimization level | O3 | O3 | O3 |
| Memory library | jemalloc | jemalloc | jemalloc |
| -march | RV64GCB | RV64GCB | RV64GCB |
| -ffp-contraction | fast | fast | fast |
| Linker optimization | - | -flto | -flto |
| Floating-point optimization | - | -ffast-math | -ffast-math |
| -mcpu | - | - | xiangshan-kunminghu |
Note: We use SimPoint to sample the programs and create checkpoint images based on our custom checkpoint format, with a SimPoint clustering coverage of 100%. The above scores are estimates based on program segments, not full SPEC CPU2006 evaluations, and may differ from actual chip performance.
Related links
- XiangShan technical discussion QQ group: 879550595
- XiangShan technical discussion website: https://github.com/OpenXiangShan/XiangShan/discussions
- XiangShan Documentation: https://xiangshan-doc.readthedocs.io/
- XiangShan User Guide: https://docs.xiangshan.cc/projects/user-guide/
- XiangShan Design Doc: https://docs.xiangshan.cc/projects/design/
Editors: Zhihao Xu, Junxiong Ji, Zhuo Chen, Junjie Yu, Yanjun Li