[XiangShan Biweekly 100] 20260413
Welcome to XiangShan biweekly column! Through this column, we will regularly share the latest development progress of XiangShan. This is the 100th issue of the biweekly report.
Before we knew it, XiangShan Biweekly has reached its 100th issue. At this special milestone, the XiangShan project also welcomes an important new member: XiangShan AI (XSAI), a unified general-purpose-and-inference AI processor implemented on top of XiangShan’s open-source, high-performance RISC-V processor. Starting from this issue, the biweekly will include XSAI development updates.
XSAI is the XiangShan team’s exploration of unified general-purpose-and-inference AI chips on top of its existing RISC-V CPU ecosystem, and a practical application of XiangShan’s agile development methodology. The Beijing Institute of Open Source Chip, together with the Microprocessor Technology Research Center and the Center for Advanced Computer Systems at the Institute of Computing Technology, Chinese Academy of Sciences, jointly participate in XSAI development. Like XiangShan, XSAI is also a fully open-source project, and its repository is available at https://github.com/OpenXiangShan/XSAI. In 2026, we will gradually release instruction extension manuals, architecture documentation, and user manuals, and open-source our development toolchain.
In addition, we would like to give you a sneak peek that the XiangShan tutorial at ISCA 2026 in Raleigh, USA at the end of June will also include content on the XSAI unified general-purpose-and-inference processor for the first time. We look forward to seeing you there!
As for recent XiangShan core development, the frontend optimized branch predictor timing, while backend and memory teams fixed bugs and continued module refactoring and testing.
XSAI
If you still remember, we presented a dedicated XSAI talk at the 2025 RISC-V China Summit (XSAI(ξ): Hardware Support for Modern LLM Kernels in a CPU Paradigm); the current XSAI is the ongoing evolution of that work.
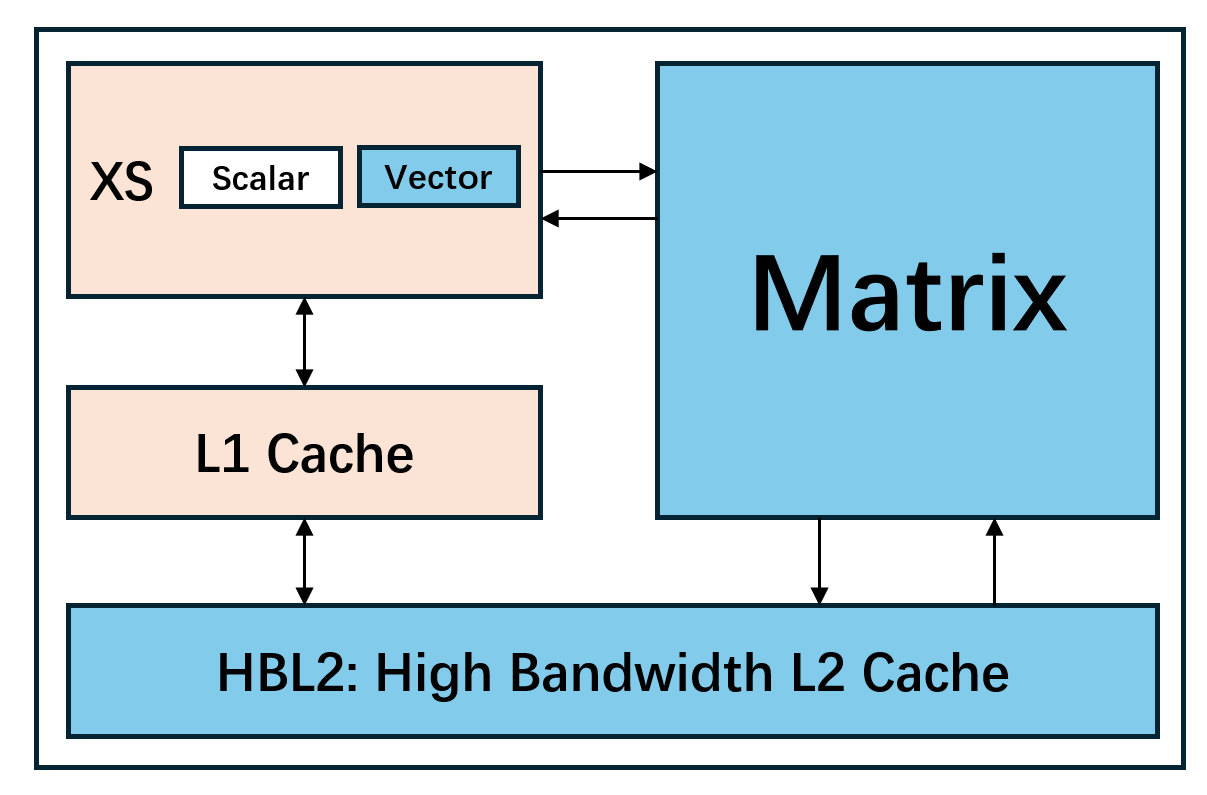
XSAI is currently developed on Kunming Lake V2R2, under the name Kunming Lake V2R2A. Compared with Kunming Lake V2R2, Kunming Lake V2R2A introduces the following features:
- Vector: The XSAI vector unit will support low-precision data types and special functions commonly used in AI workloads. V2R2A plans to support bf16 and fp8 data types, and also supports exp2 to accelerate softmax in LLMs.
- Matrix: The XSAI matrix unit is controlled by the Kunminghu core and directly interacts with the L2 cache to load/store matrix data. The V2R2A matrix unit is still under iteration and is expected to finally support bf16/fp8/int8 matrix multiply-accumulate operations. Future XSAI versions will also support data types such as mxfp8/mxfp4. Most matrix instructions are asynchronous and can execute in parallel with vector operations in the Kunminghu core, improving compute utilization.
- Cache: For matrix-compute and high-performance CPU co-execution scenarios, XSAI introduces a high-bandwidth L2 cache (HBL2). The HBL2 target parameters are 1-2MB capacity and 256-512 Bytes/cycle bandwidth. To reduce coherence overhead when coherent cache and GEMM run in parallel, XSAI further adopts access semantics and permission policies that better match matrix dataflow, thereby improving bandwidth utilization.
The XSAI group has recently run preliminary tests aimed at validating XSAI’s general-purpose and AI compute capabilities. This issue reports those test results to readers of the biweekly.
We used SPEC CPU 2006 to evaluate XSAI’s general-purpose compute capability. The checkpoints, processor parameters, and SoC parameters for this run match those in XiangShan Biweekly 91.
| SPECint 2006 @ 3GHz | V2R2A | V2R2 | SPECfp 2006 @ 3GHz | V2R2A | V2R2 |
|---|---|---|---|---|---|
| 400.perlbench | 36.03 | 36.18 | 410.bwaves | 67.35 | 66.73 |
| 401.bzip2 | 25.75 | 25.46 | 416.gamess | 40.61 | 40.99 |
| 403.gcc | 48.15 | 48.00 | 433.milc | 44.38 | 45.12 |
| 429.mcf | 63.26 | 60.63 | 434.zeusmp | 51.65 | 51.61 |
| 445.gobmk | 30.30 | 30.32 | 435.gromacs | 33.50 | 33.60 |
| 456.hmmer | 41.35 | 41.62 | 436.cactusADM | 46.06 | 46.19 |
| 458.sjeng | 30.25 | 30.24 | 437.leslie3d | 48.31 | 47.97 |
| 462.libquantum | 126.54 | 122.43 | 444.namd | 28.82 | 28.86 |
| 464.h264ref | 56.49 | 56.58 | 447.dealII | 73.37 | 73.55 |
| 471.omnetpp | 42.32 | 41.77 | 450.soplex | 52.85 | 52.50 |
| 473.astar | 29.23 | 29.19 | 453.povray | 53.05 | 53.46 |
| 483.xalancbmk | 71.39 | 72.84 | 454.Calculix | 16.35 | 16.37 |
| GEOMEAN | 44.92 | 44.66 | 459.GemsFDTD | 38.31 | 38.60 |
| 465.tonto | 36.65 | 36.66 | |||
| 470.lbm | 91.30 | 91.94 | |||
| 481.wrf | 40.25 | 40.70 | |||
| 482.sphinx3 | 48.88 | 49.13 | |||
| GEOMEAN | 44.72 | 44.85 |
Takeaway: The 3GHz V2R2A frequency is only a simulation setting, chosen to match V2R2 simulation and check that XSAI changes do not cause large performance regressions. We expect XSAI silicon to run below 3GHz. For general-purpose workloads, differences mainly come from the high-bandwidth L2 design and changes to the cache replacement policy. Overall, these results suggest XSAI’s changes do not materially affect XiangShan’s baseline general-purpose behavior or performance.
For AI inference, we ran Llama-2 15M on an XCVU19p FPGA using a trimmed V2R2A. XSAI ran at 50MHz, matrix int8 throughput is 4 TOPS/GHz, memory DDR4-2400. Measured Prefill and Decode throughput were 343.61 tok/s and 36.24 tok/s respectively; outputs matched expectations.
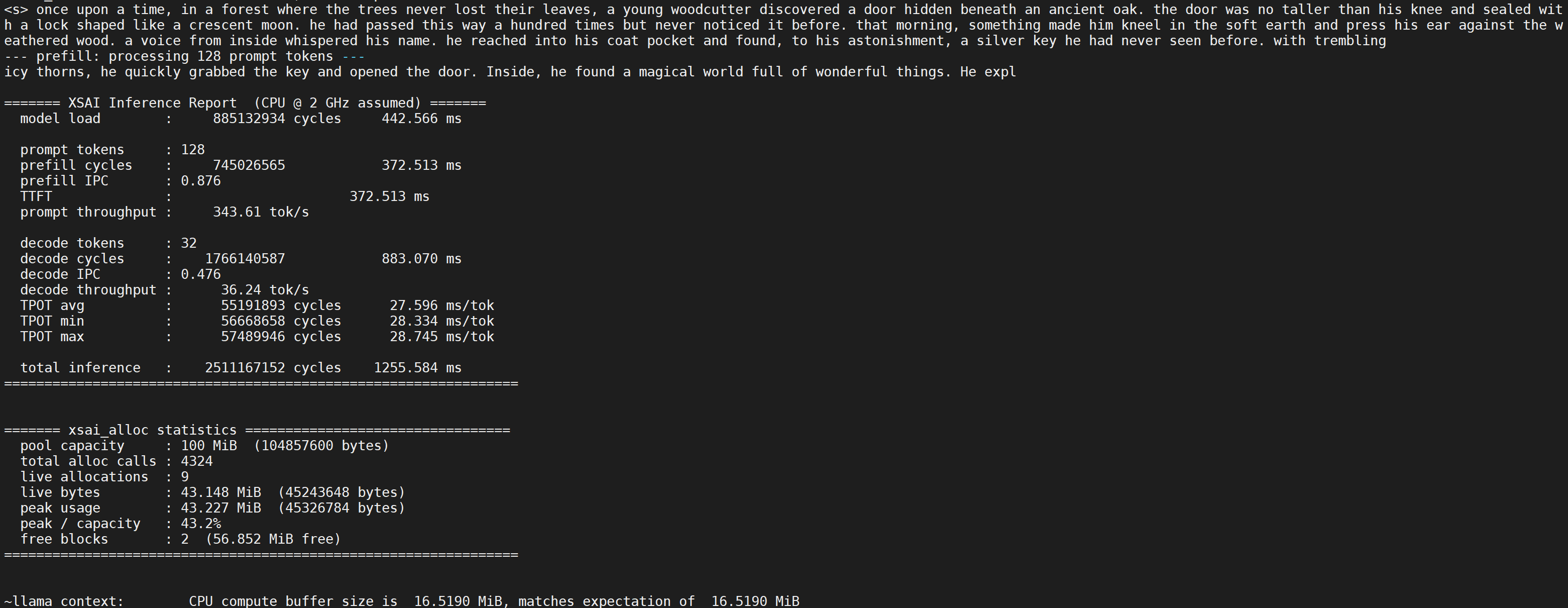
Takeaway: The memory frequency used in the test is 2400MT/s, while XSAI’s frequency is 50MHz, so extrapolating data at 50MHz to 2GHz would lead to an overly optimistic effective memory frequency. However, V2R2A has been heavily trimmed to fit on the XCVU19p, which hurts performance, making the results pessimistic. Therefore, this test serves only as a functional prototype test, demonstrating that XSAI supports LLM inference in terms of functionality.
Recent Developments
Frontend
- RTL features
- Use more precise sumAboveThreshold logic for SC (#5716)
- Enable SC Global table (#5756)
- Bug fixes
- Fix the issue where metadata of the history register is updated incorrectly when an override from the advanced predictor occurs (#5756)
- PPA optimizations
- Expose SRAMTemplate resetState to the interface, allowing BPU to determine if SRAM is ready to receive requests (#5735,Utility#141)
- More timing fixes are under evaluation
- Code quality
- Refactor the parameter related to SC table indexing (#5756)
- Debugging tools
- Make Topdown Accurate Again! Collaboratively rewrite the Top-Down performance counters with the backend team (#5564)
- Fix the issue where the condition for the BPU top-level
train_stallcounter is always false (#5734)
Backend
- RTL New Features
- Increased the size of the integer RegCache to 24 to support a 6-ALU configuration (#5613)
- Modified
vsetvl x0, x0to ensure that reserved cases behave consistently with Spike (#5744) - Bug Fixes
- Preserved
dpcduring debug re-entry following a critical error (#5730) - Synchronized fixes for debug-related bugs in V2 (#5754)
- Fixed issues related to
Mcontrol6/Tdata1(#5722) - Fixed
mis_predandtotal_flushmetrics within the TopDown analysis (#5762) - Fixed the driver for
psrcVlin the Bypass stage, changing it topdestVl(#5743) - Timing Optimizations
- Optimized timing for the Rename stage (#5685)
- Code Quality
- Renamed
halttowfi(#4512)
MemBlock and Cache
- RTL New Features
- Refactoring and testing of MMU, L2, and other modules are continuously progressing
- Optimize the Stream prefetcher by enabling decr mode and improving the training strategy (#5691)
- Modify the interface of the TL2CHICoupledL2 top-level module by changing io_cpu_halt to io_cpu_wfi (CoupledL2 #482)
- Add NextLine prefetcher (CoupledL2 #477)
- Bug Fixes
- Fix the issue of deqPtr moving too early in the StoreQueue (#5748)
- Fix the issue with pbmt and hypervisor accessing device regions (#5751)
- Fix the issue of unalignedHead getting stuck during replay (#5783)
- Code quality
- Refactor the related Bundles of storeEvent (#5763)
- Refactor the dependency relationship between CoupledL2, OpenLLC, and HuanCun repositories. In progress
- Timing Fixes
- Fix the timing issue of StoreQueue (#5698)
Performance Evaluation
Processor and SoC parameters are as follows:
| Parameters | Options |
|---|---|
| Commit | 5623d8c51 |
| Date | 2026/04/10 |
| L1 ICache | 64KB |
| L1 DCache | 64KB |
| L2 Cache | 1MB |
| L3 Cache | 16MB |
| LSU | 3ld2st |
| Bus protocol | CHI |
| Memory configuration | DDR4-3200 |
The SPEC CPU2006 scores are as follows:
| SPECint 2006 @ 3GHz | GCC15 | XSCC | SPECfp 2006 @ 3GHz | GCC15 | XSCC |
|---|---|---|---|---|---|
| 400.perlbench | 48.46 | 47.52 | 410.bwaves | 85.07 | 89.73 |
| 401.bzip2 | 27.54 | 28.34 | 416.gamess | 57.00 | 53.07 |
| 403.gcc | 55.36 | 38.89 | 433.milc | 64.79 | 63.91 |
| 429.mcf | 60.93 | 56.03 | 434.zeusmp | 70.40 | 64.16 |
| 445.gobmk | 39.33 | 40.54 | 435.gromacs | 36.44 | 34.31 |
| 456.hmmer | 53.78 | 64.07 | 436.cactusADM | 75.68 | 86.41 |
| 458.sjeng | 39.51 | 39.83 | 437.leslie3d | 56.40 | 56.59 |
| 462.libquantum | 135.75 | 294.37 | 444.namd | 42.72 | 44.81 |
| 464.h264ref | 62.95 | 71.43 | 447.dealII | 64.62 | 69.22 |
| 471.omnetpp | 41.12 | 39.44 | 450.soplex | 51.90 | 62.70 |
| 473.astar | 31.07 | 30.13 | 453.povray | 73.10 | 67.30 |
| 483.xalancbmk | 74.63 | 84.42 | 454.Calculix | 43.80 | 39.64 |
| GEOMEAN | 50.96 | 54.19 | 459.GemsFDTD | 63.12 | 63.56 |
| 465.tonto | 52.39 | 34.99 | |||
| 470.lbm | 126.14 | 131.79 | |||
| 481.wrf | 55.03 | 41.57 | |||
| 482.sphinx3 | 58.52 | 61.07 | |||
| GEOMEAN | 60.80 | 58.98 |
Compilation parameters are as follows:
| Parameters | GCC15 | XSCC |
|---|---|---|
| Compiler | gcc15 | xscc |
| Optimization level | O3 | O3 |
| Memory library | jemalloc | jemalloc |
| -march | RV64GCB | RV64GCB |
| -ffp-contraction | fast | fast |
| Linker optimization | -flto | -flto |
| Floating-point optimization | -ffast-math | -ffast-math |
| -mcpu | - | xiangshan-kunminghu |
Note: We use SimPoint to sample the programs and create checkpoint images based on our custom checkpoint format, with a SimPoint clustering coverage of 100%. The above scores are estimates based on program segments, not full SPEC CPU2006 evaluations, and may differ from actual chip performance.
Related links
- XiangShan technical discussion QQ group: 879550595
- XiangShan technical discussion website: https://github.com/OpenXiangShan/XiangShan/discussions
- XiangShan Documentation: https://xiangshan-doc.readthedocs.io/
- XiangShan User Guide: https://docs.xiangshan.cc/projects/user-guide/
- XiangShan Design Doc: https://docs.xiangshan.cc/projects/design/
Editors: Zhihao Xu, Junxiong Ji, Zhuo Chen, Junjie Yu, Jiru Sun, Yanjun Li