二级模块 L1 TLB
设计规格
- 支持接收 Frontend 和 MemBlock 的地址翻译请求
- 支持 PLRU 替换算法
- 支持向 Frontend 和 MemBlock 返回物理地址
- ITLB 和 DTLB 均采用非阻塞式访问
- ITLB 和 DTLB 项均采用寄存器堆实现
- ITLB 和 DTLB 项均为全相联结构
- ITLB 和 DTLB 分别采用处理器当前特权级和访存执行有效特权级
- 支持在 L1 TLB 内部判断虚存是否开启以及两个阶段翻译是否开启
- 支持向 L2 TLB 发送 PTW 请求
- DTLB 支持复制查询返回的物理地址
- 支持异常处理
- 支持 TLB 压缩
- 支持 TLB Hint 机制
- 存储四种类型的 TLB 项
- TLB refill 将两个阶段的页表进行融合
- TLB 项的 hit 的判断逻辑
- 支持客户机缺页后重新发送 PTW 获取 gpaddr
功能
接收 Frontend 和 MemBlock 的地址翻译请求
在核内进行内存读写,包括前端取指和后端访存前,都需要由 L1 TLB 进行地址翻译。因物理距离较远,并且为了避免相互污染,分为前端取指的 ITLB(Instruction TLB)和后端访存的 DTLB(Data TLB)。ITLB 采用全相联模式,48 项全相联保存全部大小页。ITLB 接收来自 Frontend 的地址翻译请求,itlb_requestors(0) 至 itlb_requestors(2) 来自 icache,其中 itlb_requestors(2) 为 icache 的预取请求;itlb_requestors(3) 来自 ifu,为 MMIO 指令的地址翻译请求。
| 项名 | 项数 | 组织结构 | 替换算法 | 存储内容 |
|---|---|---|---|---|
| Page | 48 | 全相联 | PLRU | 全部大小页 |
| 序号 | 来源 |
|---|---|
| requestors(0) | Icache, mainPipe |
| requestors(1) | Icache, mainPipe |
| requestors(2) | Icache, fdipPrefetch |
| requestors(3) | IFU |
香山的访存通道访存拥有 2 个 Load 流水线,2 个 Store 流水线,以及 SMS 预取器、L1 Load stream & stride 预取器。为应对众多请求,两条 Load 流水线及 L1 Load stream & stride 预取器使用 Load DTLB,两条 Store 流水线使用 Store DTLB,预取请求使用 Prefetch DTLB,共 3 个 DTLB,均采用 PLRU 替换算法(参见 5.1.1.2 节)。
DTLB 采用全相联模式,48 项全相联保存全部大小页。DTLB 接收来自 MemBlock 的地址翻译请求,dtlb_ld 接收来自 loadUnits 和 L1 Load stream & stride 预取器的请求,负责 Load 指令的地址翻译;dtlb_st 接收 StoreUnits 的请求,负责 Store 指令的地址翻译。特别地,对于 AMO 指令,会使用 loadUnit(0) 的 dtlb_ld_requestor,向 dtlb_ld 发送请求。SMSPrefetcher 会向单独的 DTLB 发送预取请求。
| 项名 | 项数 | 组织结构 | 替换算法 | 存储内容 |
|---|---|---|---|---|
| Page | 48 | 全相联 | PLRU | 全部大小页 |
| 模块 | 序号 | 来源 |
|---|---|---|
| DTLB_LD | ||
| ld_requestors(0) | loadUnit(0), AtomicsUnit | |
| ld_requestors(1) | loadUnit(1) | |
| ld_requestors(2) | loadUnit(2) | |
| ld_requestors(3) | L1 Load stream & stride Prefetch | |
| DTLB_ST | ||
| st_requestors(0) | StoreUnit(0) | |
| st_requestors(1) | StoreUnit(1) | |
| DTLB_PF | ||
| pf_requestors(0) | SMSPrefetch | |
| pf_requestors(1) | L2 Prefetch |
采用 PLRU 替换算法
L1 TLB 采用可配置的替换策略,默认为 PLRU 替换算法。在南湖架构中,ITLB 和 DTLB 均包括 NormalPage 和 SuperPage,回填策略较复杂。南湖架构 ITLB 的 NormalPage 负责 4KB 大小页的地址转换,SuperPage 负责 2MB 和 1GB 大小页的地址转换,需要根据回填的页大小(4KB,2MB 或 1GB)填入 NormalPage 或 SuperPage。南湖架构 DTLB 的 NormalPage 负责 4KB 大小页的地址转换,SuperPage 负责全部页大小的地址转换。NormalPage 为直接映射,虽然项数较多,但利用度较低。SuperPage 为全相联,利用率较高,但由于时序限制项数较少,缺失率很高。
请注意,昆明湖架构对上述问题提出优化,在满足时序的条件下,将 ITLB 和 DTLB 统一设置为 48 项全相联结构,任意大小的页都可以回填,ITLB 和 DTLB 均采用 PLRU 替换策略。
ITLB 和 DTLB 的回填策略如 此表 所示。
| 模块 | 项名 | 策略 |
|---|---|---|
| ITLB | ||
| Page | 48 项全相联,可以回填任意大小的页 | |
| DTLB | ||
| Page | 48 项全相联,可以回填任意大小的页 |
向 Frontend 和 MemBlock 返回物理地址
在 L1 TLB 通过虚拟地址得到物理地址后,会向 Frontend 和 MemBlock 返回相应请求的物理地址,以及请求是否发生 miss,是否发生 guest page fault,page fault,access fault 等信息。对于 Frontend 或 MemBlock 中的每个请求,都会由 ITLB 或 DTLB 发送回复,通 tlb_requestor(i)_resp_valid 表示回复有效。
在南湖架构中,虽然 SuperPage 和 NormalPage 在物理上都采用寄存器堆实现,但 SuperPage 是 16 项全相联结构,NormalPage 是直接相联结构。在从直接相联的 NormalPage 读出数据之后,还需要进行 tag 的比较。尽管 SuperPage 全相联项数为 16,但每次只可能命中一项,并通过 hitVec 标记命中,选择 SuperPage 中读出的数据。NormalPage 读出数据+tag 比较的时间要比 SuperPage 读出数据 + 选择数据长很多。因此,从时序方面考虑,dtlb 会向 MemBlock 返回 fast_miss 信号,表示 SuperPage 未命中;miss 信号表示 SuperPage 和 NormalPage 均未命中。
同时,在南湖架构中,由于 DTLB 的 PMP & PMA 检查时序紧张,需要将 PMP 分为动态检查和静态检查两部分。(参见 5.4 节)当 L2 TLB 的页表项回填入 DTLB 时,同时将回填的页表项送给 PMP 和 PMA 进行权限检查,将检查得结果同时存储在 DTLB 中,DTLB 需要额外向 MemBlock 返回表示静态检查有效的信号以及检查结果。
需要注意的是,昆明湖架构优化了 TLB 查询的项配置和相应时序,目前 fast_miss 被取消,且无需额外的静态 PMP & PMA 检查。但可能后续由于时序或其他原因重新恢复,因此出于文档的完整和兼容性将前两段保留。昆明湖架构取消了 fast_miss 以及静态 PMP & PMA 检查,请再次注意。
阻塞式访问和非阻塞式访问
在南湖架构中,前端取指对 ITLB 的需求为阻塞式访问,而后端访存对 DTLB 的需求为非阻塞式访问。事实上,TLB 本体是非阻塞式访问,并不存储请求的信息。TLB 采用阻塞式访问或非阻塞式访问的原因是请求来源的需求,前端取指当 TLB miss 后,需要等待 TLB 取回结果,才能将指令送至处理器后端进行处理,呈现阻塞时的效果;而访存操作可以乱序调度,当一个请求缺失后,可以调度另一个 load / store 指令继续执行,因此呈现出非阻塞式的效果。
南湖架构的上述功能通过 TLB 实现,TLB 会通过一些控制逻辑,当 ITLB 发生缺失后,持续等待通过 PTW 取回页表项。昆明湖的上述功能通过 ICache 保证,当 ITLB 发生缺失、并报给 ICache 后,ICache 会持续重发同一条请求,直至 hit,保证非阻塞式访问的效果。
但需要注意,昆明湖架构的 ITLB 和 DTLB 都是非阻塞的,无论外部效果是阻塞式或非阻塞式,均由取指单元或访存单元控制。
L1 TLB 表项的存储结构
香山的 TLB 可以对组织结构进行配置,包括相联模式、项数及替换策略等。默认配置为:ITLB 和 DTLB 均为 48 项全相联结构,且均由寄存器堆实现(参见 5.1.2.3 节)。如果在同一拍对某地址同时读写,可以通过 bypass 直接得到结果。
参考的 ILTB 或 DTLB 配置:均采用全相联结构,项数 8 / 16 / 32 / 48。目前并不支持参数化修改全相联 / 组相联 / 直接映射的 TLB 结构,需要手动修改代码。
支持在 L1 TLB 内部判断虚存是否开启以及两个阶段翻译是否开启
香山支持 RISC-V 手册中的 Sv39 页表,虚拟地址长度为 39 位。香山的物理地址为 36 位,可参数化修改。
虚存是否开启需要根据特权级和 SATP 寄存器的 MODE 域等共同决定,这一判断在 TLB 内部完成,对 TLB 外透明。关于特权级的描述,参见 5.1.2.7 节;关于 SATP 的 MODE 域,香山的昆明湖架构只支持 MODE 域为 8,也就是 Sv39 分页机制,否则会上报 illegal instruction fault。在 TLB 外的模块(Frontend、LoadUnit、StoreUnit、AtomicsUnit 等)看来,所有地址都经过了 TLB 的地址转换。
当添加了 H 拓展后,地址翻译是否启用还需要判断是否有两阶段地址翻译,两阶段地址翻译开启有两个请求,第一个是此时执行的是虚拟化访存指令,第二个是虚拟化模式开启并且此时 VSATP 或者 HGATP 的 MODE 不为零。此时的翻译模式有以下几种。翻译模式用于在 TLB 中查找对应类型的页表以及向 L2TLB 发送的 PTW 请求。
| VSATP Mode | HGATP Mode | 翻译模式 |
|---|---|---|
| 非 0 | 非 0 | allStage,两个阶段翻译均有 |
| 非 0 | 0 | onlyStage1,只有第一阶段的翻译 |
| 0 | 非 0 | onlyStage2,只有第二阶段的翻译 |
L1 TLB 的特权级
根据 Riscv 手册要求,前端取指(ITLB)的特权级为当前处理器特权级,后端访存(DTLB)的特权级为访存执行有效特权级。当前处理器特权级和访存执行有效特权级均在 CSR 模块中判断,传递到 ITLB 和 DTLB 中。当前处理器特权级保存在 CSR 模块中;访存执行有效特权级由 mstatus 寄存器的 MPRV、MPV 和 MPP 位以及 hstatus 的 SPVP 共同决定。如果执行虚拟化访存指令,则访存执行有效特权级为 hstatus 的 SPVP 位保存的特权级,如果执行的指令不是虚拟化访存指令,MPRV 位为 0,则访存执行有效特权级和当前处理器特权级相同,访存执行有效虚拟化模式也与当前虚拟化模式一致;如果 MPRV 位为 1,则访存执行有效特权级为 mstatus 寄存器的 MPP 中保存的特权级,访存执行有效虚拟化模式位 hstatus 寄存器的 MPV 保存的虚拟化模式。ITLB 和 DTLB 的特权级如表所示。
| 模块 | 特权级 |
|---|---|
| ITLB | 当前处理器特权级 |
| DTLB | 执行非虚拟化访存指令,如果 mstatus.MPRV=0,为当前处理器特权级和虚拟化模式;如果 mstatus.MPRV=1,为 mtatus.MPP 保存的特权级和 hstatus.MPV 保存的虚拟化模式 |
发送 PTW 请求
当 L1 TLB 发生 miss 时,需要向 L2 TLB 发送 Page Table Walk 请求。由于 L1 TLB 和 L2 TLB 之间有比较长的物理距离,因此需要在中间加拍,称为 Repeater。另外,repeater 需要承担过滤掉重复请求,避免 L1 TLB 中出现重复项的功能。(参见 5.2 节)因此,ITLB 或 DTLB 的第一级 Repeater 也被称作 Filter。L1 TLB 通过 Repeater 向 L2 TLB 发送 PTW 请求与接收 PTW 回复。(参见 5.3 节)
DTLB 复制查询返回的物理地址
在物理实现中,Memblock 的 dcache 与 lsu 距离较远,如果在 LoadUnit 的 load_s1 阶段产生 hitVec,再分别送往 dcache 和 lsu 会导致严重的时序问题。因此,需要并行在 dcache 和 lsu 附近产生两个 hitVec,分别送往 dcache 和 lsu。为配合解决 Memblock 的时序问题,DTLB 需要将查询得到的物理地址复制 2 份,分别送往 dcache 和 lsu,送往 dcache 和 lsu 的物理地址完全相同。
异常处理机制
ITLB 可能产生的异常包括 inst guest page fault、inst page fault 和 inst access fault,均交付给请求来源的 ICache 或 IFU 进行处理。DTLB 可能产生的异常包括:load guest page fault、load page fault、load access fault、store guest page fault、store page fault 和 store access fault,均交付给请求来源的 LoadUnits、StoreUnits 或 AtomicsUnit 进行处理。L1TLB 没有存储 gpaddr,所以出现客户机缺页时,需要重新进行 PTW。参见本文档的第 6 部分:异常处理机制。
这里需要对虚实地址转换相关的异常做额外补充说明,我们这里将异常分类如下:
- 与页表相关的异常
- 处于非虚拟化情况,或虚拟化的 VS-Stage 时,页表出现保留位不为 0 / 非对齐 / 写没有 w 权限等等(具体参见手册),需要上报 page fault
- 处于虚拟化阶段的 G-Stage 时,页表出现保留位不为 0 / 非对齐 / 写没有 w 权限等等(具体参见手册),需要上报 guest page fault
- 与虚拟地址或物理地址相关的异常
- 地址翻译过程中,与虚拟地址或物理地址相关的异常。这部分检查会在 L2 TLB 的 PTW 过程中进行。
- 处于非虚拟化情况,或虚拟化的 all-Stage 时,需要检查 G-stage 的 gvpn。如果 hgatp 的 mode 为 8(代表 Sv39x4),则需要 gvpn 的(41 - 12 = 29)位以上全部为 0;如果 hgatp 的 mode 为 9(代表 Sv48x4),则需要 gvpn 的(50 - 12 = 38)位以上全部为 0。否则,会上报 guest page fault。
- 在地址翻译得到页表时,页表的 PPN 部分高(48-12=36)位以上全部为 0。否则,会上报 access fault。
- 原始地址中,虚拟地址或物理地址相关的异常,具体总结如下,这部分理论上均需要在 L1 TLB 做检查,但由于 ITLB 的 redirect 结果完全来自 Backend,因此 ITLB 相应的这部分异常会在 Backend 发送 redirect 给 Frontend 时做记录,并不会在 ITLB 中再次检查,请参考 Backend 对此处的说明。
- Sv39 模式:包括开启虚存,且未开启虚拟化,此时 satp 的 mode 为 8;或开启虚存,且开启虚拟化,此时 vsatp 的 mode 为 8 这两种情况。此时需要满足 vaddr 的 [63:39] 位与 vaddr 的第 38 位符号相同,否则需要根据取指 / load / store 请求,分别报 instruction page fault,load page fault,store page fault。
- Sv48 模式:包括开启虚存,且未开启虚拟化,此时 satp 的 mode 为 9;或开启虚存,且开启虚拟化,此时 vsatp 的 mode 为 9 这两种情况。此时需要满足 vaddr 的 [63:48] 位与 vaddr 的第 47 位符号相同,否则需要根据取指 / load / store 请求,分别报 instruction page fault,load page fault,store page fault。
- Sv39x4 模式:开启虚存,且开启虚拟化,满足 vsatp 的 mode 为 0,且 hgatp 的 mode 为 8。(注:当 vsatp 的 mode 为 8 / 9,hgatp 的 mode 为 8 时,第二阶段地址翻译也为 Sv39x4 模式,也可能产生相应异常。但这部分属于“地址翻译过程中,与虚拟地址或物理地址相关的异常”,会在 L2 TLB 的页表遍历过程中进行处理,不属于 L1 TLB 的处理范畴。L1 TLB 只会额外处理“原始地址中,虚拟地址或物理地址相关的异常”)此时需要满足 vaddr 的 [63:41] 位全部为 0,否则需要根据取指 / load / store 请求,分别报 instruction guest page fault,load guest page fault,store guest page fault。
- Sv48x4 模式:开启虚存,且开启虚拟化,满足 vsatp 的 mode 为 0,且 hgatp 的 mode 为 9。(注:当 vsatp 的 mode 为 8 / 9,hgatp 的 mode 为 9 时,第二阶段地址翻译也为 Sv48x4 模式,也可能产生相应异常。但这部分属于“地址翻译过程中,与虚拟地址或物理地址相关的异常”,会在 L2 TLB 的页表遍历过程中进行处理,不属于 L1 TLB 的处理范畴。L1 TLB 只会额外处理“原始地址中,虚拟地址或物理地址相关的异常”)此时需要满足 vaddr 的 [63:50] 位全部为 0,否则需要根据取指 / load / store 请求,分别报 instruction guest page fault,load guest page fault,store guest page fault。
- Bare 模式:未开启虚存,此时 paddr = vaddr。由于香山处理器的物理地址目前限定为 48 位,因此对 vaddr 要求 [63:48] 位全部为 0,否则需要根据取指 / load / store 请求,分别报 instruction access fault,load access fault,store access fault。
为了支持对上述“原始地址中”的异常处理,L1 TLB 需要添加 fullva(64 bits)和 checkfullva(1 bit)的 input 信号。同时需要在 output 中添加 vaNeedExt 具体地:
- checkfullva 并非 fullva 的控制信号。也就是说,fullva 的内容并不止在 checkfullva 拉高时才有效。
- checkfullva 何时有效(需要拉高)
- 对于 ITLB,checkfullva 始终为 false,因此 chisel 生成 verilog 时,可能会将 checkfullva 优化掉,不会体现在 input 中。
- 对于 DTLB,对于所有 load / store / amo / vector 指令,在第一次由 Backend 发送至 MemBlock 时,需要做 checkfullva 检查。这里额外说明,“原始地址中,虚拟地址或物理地址相关的异常”是一个只针对 vaddr 的检查(对于 load / store 指令,vaddr 的计算一般为某寄存器的值 + imm 立即数计算得到的 64 bits 值),因此无需等待 TLB 命中,且当出现该检查的异常时,TLB 并不会返回 miss,代表该异常有效。因此,“在第一次由 Backend 发送至 MemBlock 时”,一定能够发现该异常并上报。对于非对齐访存,并不会进入 misalign buffer;对于 load 指令,并不会进入 load replay queue;对于 store 指令,也不会由保留站重发。因此,如果“一次由 Backend 发送至 MemBlock 时”并未发现该异常,由 load replay 重发时,一定不会出现该异常,无需做 checkfullva 检查。对于预取指令,不会拉高 checkfullva。
- fullva 何时有效(在什么时候被使用)
- 除一种特定情况外,fullva 只在 checkfullva 为高时有效,代表要检查的完整 vaddr。这里需要说明,一条 load / store 指令,计算得到的原始 vaddr 为 64 位(寄存器读出来的值就是 64 位的);但查询 TLB 只会用到低 48 / 50 位(Sv48 / Sv48x4),查询异常需要用到完整的 64 位。
- 特定情况:非对齐指令出现 gpf,需要获取 gpaddr。目前访存侧对非对齐异常的处理逻辑如下:
- 例如,原始 vaddr 为 0x81000ffb,要 ld 8 bytes 数据
- misalign buffer 会将该指令拆成 vaddr 为 0x81000ff8(load 1)和 0x81001000(load 2)的两条 load,且这两条 load 并不属于同一虚拟页
- 对于 load 1,此时传入 TLB 的 vaddr 为 0x81000ff8,fullva 总为原始 vaddr 0x81000ffb;对于 load 2,此时传入 TLB 的 vaddr 为 0x81001000,fullva 总为原始 vaddr 0x81000ffb
- load 1 如果出现异常,写入 tval 寄存器的 offset 约定为原始 addr 的 offset(即 0xffb);load 2 如果出现异常,写入 tval 寄存器的 offset 约定为下一页的起始值(0x000)。对于虚拟化场景的 onlyStage2 情况,此时 gpaddr = 出现异常的 vaddr。因此,对于跨页的非对齐请求、且跨页后的地址出现异常,gpaddr 的生成只会用到 vaddr(此时 offset 其实为 0x000),不会用到 fullva;对于非跨页的非对齐请求,或对于跨页、且原始地址出现异常的非对齐请求,gpaddr 的生成会用到 fullva 的 offset(0xffb)。这里 fullva 始终是有效的,和 checkfullva 是否拉高无关。
- vaNeedExt 何时有效(在什么情况被使用)
- 在访存队列 load queue / store queue 中,处于节约面积的考虑,会将 64 位原始地址截断至 50 位保存,但在写入 tval 寄存器时,需要写入 64 位值。上文中已经介绍过,对于“原始地址中,虚拟地址或物理地址相关的异常”的异常,要保留原始完整 64 位地址;而对于其他页表相关的异常,地址本身高位是满足要求的。例如: * fullva = 0xffff,ffff,8000,0000;vaddr = 0xffff,8000,0000。Mode 为非虚拟化的 Sv39。这里原始地址并未产生异常,假设这是一个 load 请求,第一次访问 TLB 时 miss,因此该 load 会进入 load replay queue 等待重发,且地址会被截断为 50 位。等待 load 指令重发后,发现该页表的 V 位为 0,发生 page fault,需要将 vaddr 写入 tval 寄存器。由于地址在 load queue replay 中已经被截断,因此需要做符号位扩展(例如 Sv39 情况,即将 39 位以上扩展为 38 位的值),返回的 vaNeedExt 拉高。 * fullva = 0x0000,ffff,8000,0000;vaddr = 0xffff,8000,0000。Mode 为非虚拟化的 Sv39。这里可以发现原始地址就产生了异常,我们会将该地址直接写入对应的 exception buffer 中(exception buffer 会保存完整的 64 位值)。此时需要直接将 0x0000,ffff,8000,0000 原始值写入 *tval,不能做符号位扩展,vaNeedExt 为低。
支持 pointer masking 扩展
目前香山处理器支持 pointer masking 扩展。
pointer masking 扩展的本质是将访存的 fullva 由“寄存器堆的值 + imm 立即数”这个原始值,变为“effective vaddr”这个高位可能被忽略的值。当 pmm 的值为 2 时,会忽略高 7 位;当 pmm 的值为 3 时,会忽略高 16 位。pmm 为 0 代表不忽略高位,pmm 为 1 是保留位。
pmm 的值可能来自于 mseccfg/menvcfg/henvcfg/senvcfg 的 PMM([33:32])位,也可能来自于 hstatus 寄存器的 HUPMM([49:48])位。具体怎样选择如下:
- 对于前端取指请求,或者一条手册规定的 hlvx 指令,不会使用 pointer masking(pmm 为 0)
- 当前访存有效特权级(dmode)为 M 态,选择 mseccfg 的 PMM([33:32])位
- 非虚拟化场景,且当前访存有效特权级为 S 态(HS),选择 menvcfg 的 PMM([33:32])位
- 虚拟化场景,且当前访存有效特权级为 S 态(VS),选择 henvcfg 的 PMM([33:32])位
- 是虚拟化指令,且当前处理器特权级(imode)为 U 态,选择 hstatus 的 HUPMM([49:48])位
- 其余 U 态场景,选择 senvcfg 的 PMM([33:32])位
由于 pointer masking 的只针对访存生效,并不适用于前端取指。因此 ITLB 不存在“effective vaddr”的概念,也不会在端口中引入 CSR 传入的这些信号。
由于这些地址的高位只在上文提到的“原始地址中,虚拟地址或物理地址相关的异常”中被检查使用,因此对于屏蔽高位的情况,我们直接让其不会触发异常即可。具体地:
- 对于开启虚存的非虚拟化场景,或虚拟化场景的非 onlyStage2(vsatp 的 mode 不为 0)情况;根据 pmm 的值为 2 或 3,分别对地址的高 7 或 16 位做符号扩展
- 对于虚拟化场景的 onlyStage2 情况,或未开启虚存,根据 pmm 的值为 2 或 3,分别对地址的高 7 或 16 位做零扩展
支持 TLB 压缩
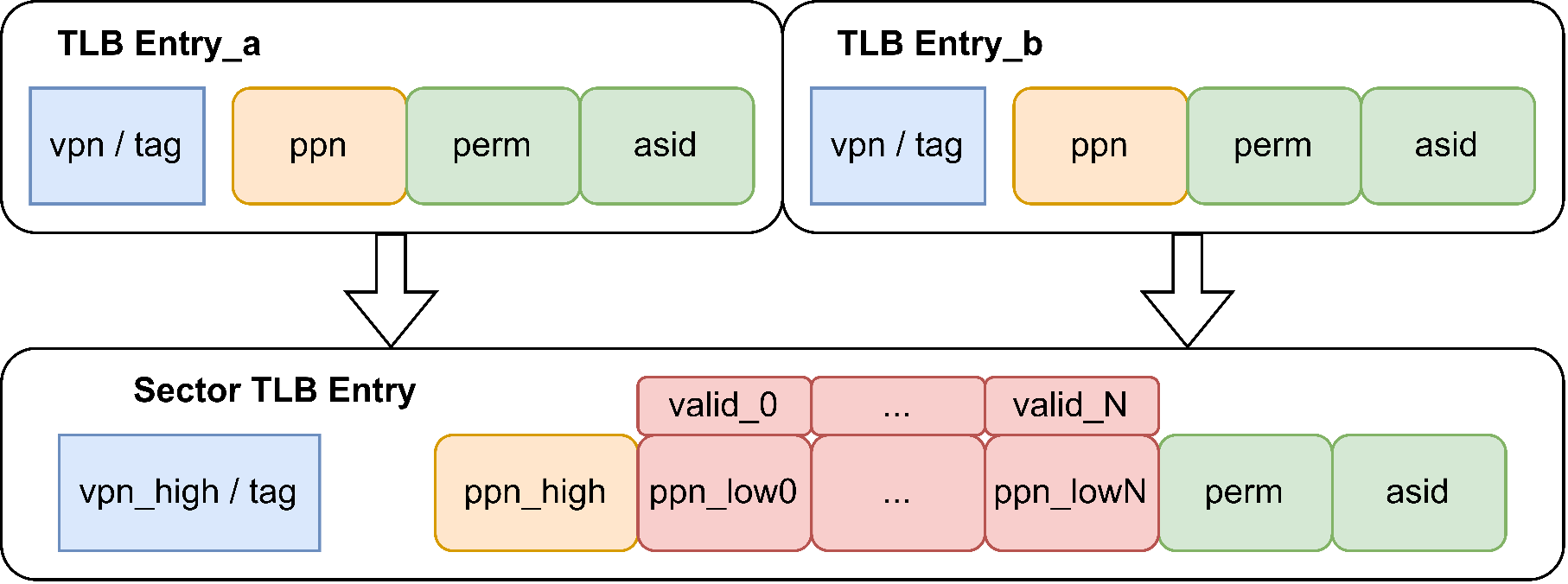
昆明湖架构支持 TLB 压缩,每项 TLB 压缩会保存连续 8 项的页表项,如图上所示。TLB 压缩的理论基础是,操作系统在分配页时,由于伙伴分配机制等原因,会更倾向将连续的物理页分配给连续的虚拟页。虽然随着程序的不断运行,页分配从有序逐渐趋向于无序,但这种页的相联性普遍存在。因此,可以将多个连续的页表项在硬件中合并成一个 TLB 项,从而起到提高 TLB 容量的作用。
也就是说,对于虚拟页号高位相同的页表项,当这些页表项的物理页号高位和页表属性也相同时,可以将这些页表项压缩为一项保存,从而提升 TLB 的有效容量。压缩后的 TLB 项共用物理页号高位以及页表属性位,每个页表单独拥有物理页号低位,并通过 valid 表示该页表在压缩后的 TLB 项中有效,如表 5.1.8。
表 5.1.8 展示了压缩前后的对比,压缩前的 tag 即为 vpn,压缩后的 tag 为 vpn 的高 24 位,低 3 位无需保存,事实上连续 8 项页表的第 i 项,i 即为 tag 的低 3 位。ppn 高 21 位相同,ppn_low 分别保存 8 项页表的 ppn 低 3 位。Valididx 表示这 8 项页表的有效性,只有 valididx(i) 为 1 时才有效。pteidx(i) 代表原始请求对应的第 i 项,即原始请求 vpn 的低 3 位的值。
这里举例进行说明。例如,某 vpn 为 0x0000154,低三位为 100,即 4。当回填入 L1 TLB 后,会将 vpn 为 0x0000150 到 0x0000157 的 8 项页表均回填,且压缩为 1 项。例如,vpn 为 0x0000154 的 ppn 高 21 位为 PPN0,页表属性位为 PERM0,如果这 8 项页表的第 i 项 ppn 高 21 位和页表属性也为 PPN0 和 PERM0,则 valididx(i) 为 1,通过 ppn_low(i) 保存第 i 项页表的低 3 位。另外,pteidx(i) 代表原始请求对应的第 i 项,这里原始请求的 vpn 低三位为 4,因此 pteidx(4) 为 1,其余 pteidx(i) 均为 0。
另外,TLB 不会对查询结果为大页(1GB、2MB)情况进行压缩。对于大页,返回时会将 valididx(i) 的每一位都设置为 1,根据页表查询规则,大页事实上不会使用 ppn_low,因此 ppn_low 的值可以为任意值。
| 是否压缩 | tag | asid | level | ppn | perm | valididx | pteidx | ppn_low |
|---|---|---|---|---|---|---|---|---|
| 否 | 27 位 | 16 位 | 2 位 | 24 位 | 页表属性 | 不保存 | 不保存 | 不保存 |
| 是 | 24 位 | 16 位 | 2 位 | 21 位 | 页表属性 | 8 位 | 8 位 | 8×3 位 |
在实现 TLB 压缩后,L1 TLB 的命中条件由 TAG 命中,变为 TAG 命中(vpn 高位匹配),同时还需满足用 vpn 低 3 位索引的 valididx(i) 有效。PPN 由 ppn(高 21 位)与 ppn_low(i) 拼接得到。
但注意的是,添加 H 拓展后,L1TLB 的项分为四种类型,TLB 压缩机制虚拟化的 TLB 项中不启用(但 TLB 压缩在 L2TLB 中仍然使用),接下来会详细介绍这四种类型。
存储四种类型的 TLB 项
在添加 H 拓展的 L1TLB 中对 TLB 项进行了修改,如 此图 所示。

与原先的设计相比,新增了 g_perm、vmid、s2xlate,其中 g_perm 用来存储第二阶段页表的 perm,vmid 用来存储第二阶段页表的 vmid,s2xlate 用来区分 TLB 项的类型。根据 s2xlate 的不同,TLB 项目存储的内容也有所不同。
| 类型 | s2xlate | tag | ppn | perm | g_perm | level |
|---|---|---|---|---|---|---|
| noS2xlate | b00 | 非虚拟化下的虚拟页号 | 非虚拟化下的物理页号 | 非虚拟化下的页表项 perm | 不使用 | 非虚拟化下的页表项 level |
| allStage | b11 | 第一阶段页表的虚拟页号 | 第二阶段页表的物理页号 | 第一阶段页表的 perm | 第二阶段页表的 perm | 两阶段翻译中最大的 level |
| onlyStage1 | b01 | 第一阶段页表的虚拟页号 | 第一阶段页表的物理页号 | 第一阶段页表的 perm | 不使用 | 第一阶段页表的 level |
| onlyStage2 | b10 | 第二阶段页表的虚拟页号 | 第二阶段页表的物理页号 | 不使用 | 第二阶段页表的 perm | 第二阶段页表的 level |
其中 TLB 压缩技术在 noS2xlate 和 onlyStage1 中启用,在其他情况下不启用,allStage 和 onlyS2xlate 情况下,L1TLB 的 hit 机制会使用 pteidx 来计算有效 pte 的 tag 与 ppn,这两种情况在重填的时候也会有所区别。此外,asid 在 noS2xlate、allStage、onlyStage1 中有效,vmid 在 allStage、onlyStage2 中有效。
TLB refill 将两个阶段的页表进行融合
添加了 H 拓展后的 MMU,PTW 返回的结构分为三部分,第一部分 s1 是原先设计中的 PtwSectorResp,存储第一阶段翻译的页表,第二部分 s2 是 HptwResp,存储第二阶段翻译的页表,第三部分是 s2xlate,代表这次 resp 的类型,仍然分为 noS2xlate、allStage、onlyStage1 和 onlyStage2,如 此图。其中 PtwSectorEntry 是采用了 TLB 压缩技术的 PtwEntry,两者的主要区别是 tag 和 ppn 的长度
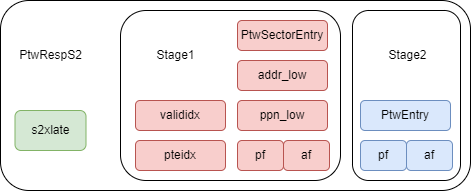
对于 noS2xlate 和 onlyStage1 的情况,只需要将 s1 的结果填入 TLB 项中即可,写入方法与原先的设计类似,将返回的 s1 的对应字段填入 entry 的对应字段即可。需要注意的是,noS2xlate 的时候,vmid 字段无效。
对于 onlyS2xlate 的情况,我们将 s2 的结果给填入 TLB 项,这里由于要符合 TLB 压缩的结构,所以需要进行一些特殊处理。首先该项的 asid、perm 不使用,所以我们不关心此时填入的什么值,vmid 填入 s1 的 vmid(由于 PTW 模块无论什么情况都会填写这个字段,所以可以直接使用这个字段写入)。将 s2 的 tag 填入 TLB 项的 tag,pteidx 根据 s2 的 tag 的低 sectortlbwidth 位来确定,如果 s2 是大页,那么 TLB 项的 valididx 均为有效,否则 TLB 项的 pteidx 对应 valididx 有效。关于 ppn 的填写,复用了 allStage 的逻辑,将在 allStage 的情况下介绍。
对于 allStage,需要将两阶段的页表进行融合,首先根据 s1 填入 tag、asid、vmid 等,由于只有一个 level,level 填入 s1 和 s2 最大的值,这是考虑到如果存在第一阶段是大页和第二阶段是小页的情况,可能会导致某个地址进行查询的时候 hit 大页,但实际已经超出了第二阶段页表的范围,对于这种请求的 tag 也要进行融合,比如第一个 tag 是一级页表,第二个 tag 是二级页表,我们需要取第一个 tag 的第一级页号与第二个 tag 的第二级页号拼合(第三级页号可以直接补零)得到新页表的 tag。此外,还需要填入 s1 和 s2 的 perm 以及 s2xlate,对于 ppn,由于我们不保存客户机物理地址,所以对于第一阶段小页和第二阶段大页的情况,如果直接存储 s2 的 ppn 会导致查询到该页表时计算得到的物理地址出错,所以首先要根据 s2 的 level 将 s2 的 tag 与 ppn 拼接一下,s2ppn 为高位 ppn,s2ppn_tmp 则是为了计算低位构造出来的,然后高位填入 TLB 项的 ppn 字段,低位填入 TLB 项的 ppn_low 字段。
TLB 项的 hit 的判断逻辑
L1TLB 中使用的 hit 有三种,查询 TLB 的 hit,填写 TLB 的 hit,以及 PTW 请求 resp 时的 hit。
对于查询 TLB 的 hit,新增了 vmid,hasS2xlate,onlyS2,onlyS1 等参数。Asid 的 hit 在第二阶段翻译的时候一直为 true。H 拓展中增加了 pteidx hit,在小页并且在 allStage 和 onlyS2 的情况下启用,用来屏蔽掉 TLB 压缩机制。
对于填写 TLB 的 hit(wbhit),输入是 PtwRespS2,需要判断当前的进行对比的 vpn,如果是只有第二阶段的翻译,则使用 s2 的 tag 的高位,其他情况使用 s1vpn 的 tag,然后在低 sectortlbwidth 位补上 0,然后使用 vpn 与 TLB 项的 tag 进行对比。H 拓展对 wb_valid 的判断进行了修改,并且新增了 pteidx_hit 和 s2xlate_hit。如果是只有第二阶段翻译的 PTW resp,则 wb_valididx 根据 s2 的 tag 来确定,否则直接连接 s1 的 valididx。s2xlate hit 则是对比 TLB 项的 s2xlate 与 PTW resp 的 s2xlate,用来筛选 TLB 项的类型。pteidx_hit 则是为了无效 TLB 压缩,如果是只有第二阶段翻译,则对比 s2 的 tag 的低位与 TLB 项的 pteidx,其他的两阶段翻译情况则对比 TLB 项的 ptedix 和 s1 的 pteidx。
对于 PTW 请求的 resp hit,主要用于 PTW resp 的时候判断此时 TLB 发送的 PTW req 是否正好与该 resp 对应或者判断在查询 TLB 的时候 PTW resp 是否是 TLB 这个请求需要的 PTW 结果。该方法在 PtwRespS2 中定义,在该方法内部分为三种 hit,对于 noS2_hit(noS2xlate),只需要判断 s1 是否 hit 即可,对于 onlyS2_hit(onlyStage2),则判断 s2 是否 hit 即可,对于 all_onlyS1_hit(allStage 或者 onlyStage1),需要重新设计 vpnhit 的判断逻辑,不能简单判断 s1hit,判断 vpn_hit 的 level 应该取用 s1 和 s2 的最大值,然后根据 level 来判断 hit,并且增加 vasid(来自 vsatp)的 hit 和 vmid 的 hit。
支持客户机缺页后重新发送 PTW 获取 gpaddr
由于 L1TLB 不保存翻译结果中的 gpaddr,所以当查询 TLB 项后出现 guest page fault 的时候需要重新进行 PTW 获取 gpaddr,此时 TLB resp 仍然是 miss。这里新增了一些寄存器。
| 名称 | 类型 | 作用 |
|---|---|---|
| need_gpa | Bool | 表示此时有一个请求正在获取 gpaddr |
| need_gpa_robidx | RobPtr | 获取 gpaddr 的请求的 robidx |
| need_gpa_vpn | vpnLen | 获取 gpaddr 的请求的 vpn |
| need_gpa_gvpn | vpnLen | 存储获取的 gpaddr 的 gvpn |
| need_gpa_refill | Bool | 表示该请求的 gpaddr 已经被填入 need_gpa_gvpn |
当一个 TLB 请求查询出来的 TLB 项出现了客户机缺页,则需要重新进行 PTW,此时会把 need_gpa 有效,将请求的 vpn 填入 need_gpa_vpn,将请求的 robidx 填入 need_gpa_robidx,初始化 resp_gpa_refill 为 false。当 PTW resp,并且通过 need_gpa_vpn 判断是之前发送的获取 gpaddr 的请求,则将 PTW resp 的 s2 tag 填入 need_gpa_gvpn,并且将 need_gpa_refill 有效,表示已经获取到 gpaddr 的 gvpn,当之前的请求重新进入 TLB 的时候,就可以使用这个 need_gpa_gvpn 来计算出 gpaddr 并且返回,当一个请求完成以上过程后,将 need_gpa 无效掉。这里的 resp_gpa_refill 依旧有效,所以重填的 gvpn 可能被其他的 TLB 请求使用(只要跟 need_gpa_vpn 相等)。
此外可能出现 redirect 的情况,导致整个指令流变化,之前获取 gpaddr 的请求不会再进入 TLB,所以如果出现 redirect 就根据我们保存的 need_gpa_robidx 来判断是否需要无效掉 TLB 内与获取 gpaddr 有关的寄存器。
此外为了保证获取 gpaddr 的 PTW 请求返回的时候不会 refill TLB,在发送 PTW 请求的时候添加了一个新的 output 信号 getGpa,该信号传递的路径与 memidx 类似,可以参考 memidx,该信号会传入 Repeater 内,当 PTW resp 回 TLB 的时候,该信号也会发送回来,如果该信号有效,则表明这个 PTW 请求只是为了获取 gpaddr,所以此时不会重填 TLB。
关于发生 guest page fault 后获取 gpaddr 的处理流程,这里对于一些关键点做再次说明:
-
可以将获取 gpa 的机制看作一个只有 1 项的 buffer,当某个请求发生 guest page fault 时,即向该 buffer 写入 need_gpa 的相应信息;直至 need_gpa_vpn_hit && resp_gpa_refill 条件有效,或传入 flush(itlb)/ redirect(dtlb)信号刷新 gpa 信息。
-
need_gpa_vpn_hit 指的是:在某个请求发生 guest page fault 后,会将 vpn 信息写入 need_gpa_vpn 中。如果相同的 vpn 再次查询 TLB,need_gpa_vpn_hit 信号会拉高,代表获取的 gpaddr 与原始 get_gpa 请求相对应。如果此时 resp_gpa_refill 也为高,代表 vpn 已经获取得到对应的 gpaddr,可以将 gpaddr 返回给前端取指 / 后端访存进行异常处理。
-
因此,对于前端或访存的任意请求,如果触发 gpa,则后续一定需要满足以下两个条件之一:
- 该触发 gpa 的请求一定能够重发(TLB 在获取 gpaddr 前,会一直对该请求返回 miss,直至得到 gpaddr 结果为止
-
需要通过向 TLB 传入 flush 或 redirect 信号,将该 gpa 请求冲刷掉。具体地,对于所有可能的请求:
- ITLB 的取指请求:如果出现 gpf 的取指请求处于推测路径上,且发现出现错误的推测,则会通过 flushPipe 信号进行刷新(包括后端 redirect、或前端多级分支预测器出现后级预测器的预测结果更新前级预测器的预测结果等);对于其他情况,由于 ITLB 会对该请求返回 miss,前端会保证重发相同 vpn 的请求。
- DTLB 的 load 请求:如果出现 gpf 的 load 请求处于推测路径上,且发现出现错误的推测,则会通过 redirect 信号进行刷新(需要判断出现 gpf 的 robidx 与传入 redirect 的 robidx 的前后关系);对于其他情况,由于 DTLB 会对该请求返回 miss,同时会将返回 tlbreplay 信号拉高,使 load queue replay 一定能够重发该请求。
- DTLB 的 store 请求:如果出现 gpf 的 store 请求处于推测路径上,且发现出现错误的推测,则会通过 redirect 信号进行刷新(需要判断出现 gpf 的 robidx 与传入 redirect 的 robidx 的前后关系);对于其他情况,由于 DTLB 会对该请求返回 miss,后端一定会调度该 store 指令再次重发该请求。
- DTLB 的 prefetch 请求:返回的 gpf 信号会拉高,代表该预取请求的地址发生 gpf,但不会写入 gpa* 一系列寄存器,不会触发查找 gpaddr 机制,无需考虑。
- 在目前的处理机制中,需要保证发生 gpf 且等待 gpa 的该 TLB 项在等待 gpa 过程中不会被替换出去。这里我们简单地在出现等待 gpa 情况时,阻止 TLB 的回填,从而避免替换操作发生。由于发生 gpf 时本就需要进行异常处理程序,且在此之后的指令会被重定向冲刷掉,因此在等待 gpa 过程中阻止回填并不会导致性能问题。
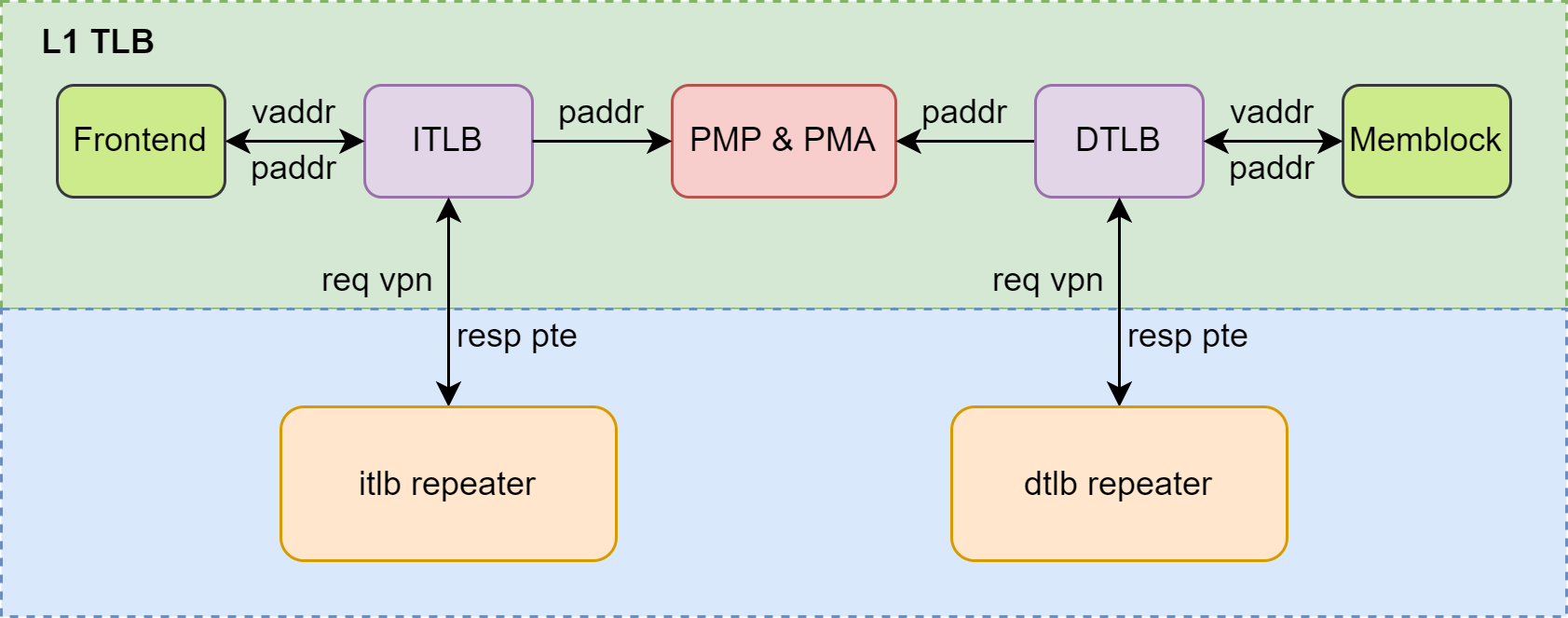
整体框图
L1 TLB 的整体框图如 此图 所述,包括绿框中的 ITLB 和 DTLB。ITLB 接收来自 Frontend 的 PTW 请求,DTLB 接收来自 Memblock 的 PTW 请求。来自 Frontend 的 PTW 请求包括 ICache 的 3 个请求和 IFU 的 1 个请求,来自 Memblock 的 PTW 请求包括 LoadUnit 的 2 个请求(AtomicsUnit 占用 LoadUnit 的 1 个请求通道)、L1 Load Stream & Stride prefetch 的 1 个请求,StoreUnit 的 2 个请求,以及 SMSPrefetcher 的 1 个请求。
在 ITLB 和 DTLB 查询得到结果后,都需要进行 PMP 和 PMA 检查。由于 L1 TLB 的面积较小,因此 PMP 和 PMA 寄存器的备份并不存储在 L1 TLB 内部,而是存储在 Frontend 或 Memblock 中,分别为 ITLB 和 DTLB 提供检查。ITLB 和 DTLB 缺失后,需要经过 repeater 向 L2 TLB 发送查询请求。
接口时序
ITLB 与 Frontend 的接口时序
Frontend 向 ITLB 发送的 PTW 请求命中 ITLB
Frontend 向 ITLB 发送的 PTW 请求在 ITLB 命中时,时序图如 此图 所示。

当 Frontend 向 ITLB 发送的 PTW 请求在 ITLB 命中时,resp_miss 信号保持为 0。req_valid 为 1 后的下一个时钟上升沿,ITLB 会将 resp_valid 信号置 1,同时向 Frontend 返回虚拟地址转换后的物理地址,以及是否发生 guest page fault、page fault 和 access fault 等信息。时序描述如下:
- 第 0 拍:Frontend 向 ITLB 发送 PTW 请求,req_valid 置 1。
- 第 1 拍:ITLB 向 Frontend 返回物理地址,resp_valid 置 1。
Frontend 向 ITLB 发送的 PTW 请求未命中 ITLB
Frontend 向 ITLB 发送的 PTW 请求在 ITLB 未命中时,时序图如 此图 所示。

当 Frontend 向 ITLB 发送的 PTW 请求在 ITLB 中未命中时,下一拍会向 ITLB 返回 resp_miss 信号,表示 ITLB 未命中。此时 ITLB 的该条 requestor 通道不再接收新的 PTW 请求,由 Frontend 重复发送该请求,直至查询得到 L2 TLB 或内存中的页表并返回。(请注意,"ITLB 的该条 requestor 通道不再接收新的 PTW 请求"由 Frontend 控制,也就是说,无论 Frontend 选择不重发 miss 的请求,或重发其他请求,Frontend 的行为对 TLB 来说是透明的。如果 Frontend 选择发送新请求,ITLB 会将旧请求直接丢失掉。)
当 Frontend 向 ITLB 发送的 PTW 请求在 ITLB 中未命中时,下一拍会向 ITLB 返回 resp_miss 信号,表示 ITLB 未命中。此时 ITLB 的该条 requestor 通道不再接收新的 PTW 请求,由 Frontend 重复发送该请求,直至查询得到 L2 TLB 或内存中的页表并返回。(请注意,"ITLB 的该条 requestor 通道不再接收新的 PTW 请求"由 Frontend 控制,也就是说,无论 Frontend 选择不重发 miss 的请求,或重发其他请求,Frontend 的行为对 TLB 来说是透明的。如果 Frontend 选择发送新请求,ITLB 会将旧请求直接丢失掉。)
当 ITLB 未命中时,会向 L2 TLB 发送 PTW 请求,直至查询得到结果。ITLB 与 L2 TLB 的时序交互,以及向 Frontend 返回的物理地址等信息参见图 4.4 的时序图以及如下的时序描述:
- 第 0 拍:Frontend 向 ITLB 发送 PTW 请求,req_valid 置 1。
- 第 1 拍:ITLB 查询得到 miss,向 Frontend 返回 resp_miss 为 1,resp_valid 置 1。同时,在当拍 ITLB 向 L2 TLB(事实上为 itlbrepeater1)发送 PTW 请求,ptw_req_valid 置 1。
- 第 X 拍:L2 TLB 向 ITLB 返回 PTW 回复,包括 PTW 请求的虚拟页号、得到的物理页号、页表信息等,ptw_resp_valid 为 1。在该拍 ITLB 已经收到 L2 TLB 的 PTW 回复,ptw_req_valid 置 0。
- 第 X+1 拍:ITLB 此时命中,resp_valid 为 1,resp_miss 为 0。ITLB 向 Frontend 返回物理地址以及是否发生 access fault、page fault 等信息。
- 第 X+2 拍:ITLB 向 Frontend 返回的 resp_valid 信号置 0。
DTLB 与 Memblock 的接口时序
Memblock 向 DTLB 发送的 PTW 请求命中 DTLB
Memblock 向 DTLB 发送的 PTW 请求在 DTLB 命中时,时序图如 此图 所示。
当 Memblock 向 DTLB 发送的 PTW 请求在 DTLB 命中时,resp_miss 信号保持为 0。req_valid 为 1 后的下一个时钟上升沿,DTLB 会将 resp_valid 信号置 1,同时向 Memblock 返回虚拟地址转换后的物理地址,以及是否发生 page fault 和 access fault 等信息。时序描述如下:
- 第 0 拍:Memblock 向 DTLB 发送 PTW 请求,req_valid 置 1。
- 第 1 拍:DTLB 向 Memblock 返回物理地址,resp_valid 置 1。
Memblock 向 DTLB 发送的 PTW 请求未命中 DTLB
DTLB 和 ITLB 相同,均为非阻塞式访问(即 TLB 内部并不包括阻塞逻辑,如果请求来源保持不变,即缺失后持续重发同一条请求,则呈现出类似阻塞式访问的效果;如果请求来源在收到缺失的反馈后,调度其他不同请求查询 TLB,则呈现出类似非阻塞式访问的效果)。和前端取指不同,当 Memblock 向 DTLB 发送的 PTW 请求未命中 DTLB,并不会阻塞流水线,DTLB 会在 req_valid 的下一拍向 Memblock 返回请求 miss 以及 resp_valid 的信号,在 Memblock 在收到 miss 信号后可以进行调度,继续查询其他请求。
在 Memblock 访问 DTLB 发生 miss 后,DTLB 会向 L2 TLB 发送 PTW 请求,查询来自 L2 TLB 或内存中的页表。DTLB 通过 Filter 向 L2 TLB 传递请求,Filter 可以合并 DTLB 向 L2 TLB 发送的重复请求,保证 DTLB 中不出现重复项并提高 L2 TLB 的利用率。Memblock 向 DTLB 发送的 PTW 请求未命中 DTLB 的时序图如 此图 所示,该图只描述了从请求 miss 到 DTLB 向 L2 TLB 发送 PTW 请求的过程。

在 DTLB 接收到 L2 TLB 的 PTW 回复后,将页表项存储在 DTLB 中。当 Memblock 再次访问 DTLB 时会发生 hit,情况与 此图 相同。DTLB 与 L2 TLB 交互的时序情况与 此图 的 ptw_req 和 ptw_resp 部分相同。
TLB 与 tlbRepeater 的接口时序
TLB 向 tlbRepeater 发送 PTW 请求
TLB 向 tlbRepeater 发送 PTW 请求的接口时序图如 此图 所示。

昆明湖架构中,ITLB 和 DTLB 均采用非阻塞访问,在 TLB miss 时会向 L2 TLB 发送 PTW 请求,但并不会因为未接收到 PTW 回复而阻塞流水线和 TLB 与 Repeater 之间的 PTW 通道。TLB 可以不断向 tlbRepeater 发送 PTW 请求,tlbRepeater 会根据这些请求的虚拟页号,对重复的请求进行合并,避免 L2 TLB 的资源浪费以及 L1 TLB 的重复项。
从 此图 的时序关系可以看出,在 tlb 向 Repeater 发送 PTW 请求后的下一拍,Repeater 会继续向下传递 PTW 请求。由于 Repeater 已经向 L2 TLB 发送过虚拟页号为 vpn1 的 PTW 请求,因此当 Repeater 再次接收到相同虚拟页号的 PTW 请求时,不会再传递给 L2 TLB。
itlbRepeater 向 ITLB 返回 PTW 回复
itlbRepeater 向 ITLB 返回 PTW 回复的接口时序图参见 此图 。

时序描述如下:
- 第 X 拍:itlbRepeater 收到通过下级 itlbRepeater 传入的 L2 TLB 的 PTW 回复,itlbrepeater_ptw_resp_valid 为高。
- 第 X+1 拍:ITLB 收到来自 itlbRepeater 的 PTW 回复。
dtlbRepeater 向 DTLB 返回 PTW 回复
dtlbRepeater 向 DTLB 返回 PTW 回复的接口时序图参见 此图 。

时序描述如下:
- 第 X 拍:dtlbRepeater 收到通过下级 dtlbRepeater 传入的 L2 TLB 的 PTW 回复,dtlbrepeater_ptw_resp_valid 为高。
- 第 X+1 拍:dtlbRepeater 将 PTW 回复传递到 memblock 中。
- 第 X+2 拍:DTLB 收到 PTW 回复。