Kunming Lake FTQ Module Documentation
Glossary of Terms
Table 1.1 Terminology
| abbreviation | Full name | Description |
|---|---|---|
| CRU | Clock Reset Unit | Clock reset unit. |
| FTQ | Fetch Target Queue. | Fetch Target Queue |
| FTB | Fetch Target Buffer | Fetch Target Buffer |
Functional Description
Functional Overview
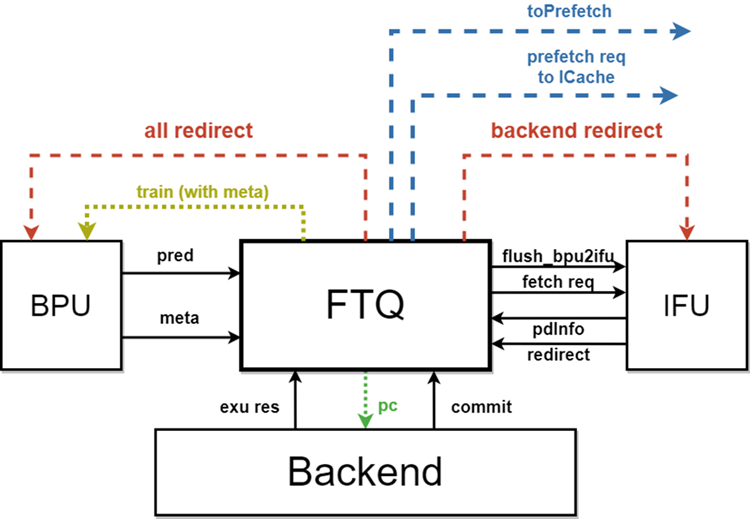
The FTQ is a buffer queue between the branch prediction unit and the instruction fetch unit. Its primary function is to temporarily store fetch targets predicted by the BPU and send fetch requests to the IFU based on these targets. Another key function is to store prediction information from various predictors in the BPU, which is later sent back to the BPU for predictor training after instruction commit. Therefore, it needs to maintain the complete lifecycle of instructions from prediction to commit.
- Supports temporarily storing BPU-predicted fetch targets and sending fetch requests to IFU.
- Supports caching BPU's prediction information and sending it back to BPU for training
- Supports redirect recovery
- Support sending prefetch requests to ICache
Temporarily stores the fetch targets predicted by the BPU and sends fetch requests to the IFU.
Temporarily stores the fetch targets predicted by BPU
Structure storing PC
A single prediction by the BPU goes through three pipeline stages, each generating new prediction content. The FTQ receives prediction results from each pipeline stage of the BPU, and the results from later stages overwrite those from earlier stages.
Instructions are issued from the BPU to the FTQ in prediction blocks, while the bpuPtr increments by one, initializing various states of the corresponding FTQ entry and writing prediction information into storage structures. If the prediction block comes from BPU's override prediction logic, the bpuPtr and ifuPtr are restored.
The fetch targets predicted by the BPU are temporarily stored in ftq_pc_mem by the FTQ:
- ftq_pc_mem: Implemented as a register file, storing information related to instruction addresses, including the following fields:
- startAddr: The starting address of the prediction block.
- nextLineAddr The starting address of the next cache line in the prediction block.
- isNextMask: Indicates whether each possible instruction start position in the prediction block falls within the next region aligned by prediction width. isNextMask has 16 bits, with each bit representing whether the 2-byte*n position relative to the start address crosses a cache line, describing the property of each position.
- fallThruError Indicates whether there is an error in the predicted next sequential fetch address.
Each field is stored in its own register (e.g., data_0_startAddr) rather than being concatenated into a single register.
Method of calculating the PC
Each fetch from the ICache retrieves one or two cache lines of instruction data (64Bytes each). Fetching two lines is determined by whether the predicted block spans across cache lines.
Each prediction block has a length of PredictWidth (16) compressed instructions (32 bytes). The length of each cache line is twice that of a prediction block, so the startAddr of each prediction block is either in the first half (startAddr[5]=0) or the second half (startAddr[5]=1) of the current cache line.
If startAddr[5]=0, the current prediction block will definitely not cross the cache line. In this case, the predicted instruction PC={startAddr[38,6], startAddr[5,1]+offset, 1'b0}.
If startAddr[5]=1, the current prediction block may span across cache lines. In this case:
- If isNextMask(offset)=0, it indicates that the current predicted instruction PC does not cross cache lines, then the predicted instruction PC = {startAddr[38,6], startAddr[5,1]+offset,1'b0}.
- If isNextMask(offset)=1, it indicates that the current predicted instruction PC crosses the cache line. In this case, the predicted instruction PC={nextLineAddr[38,6], startAddr[5,1]+offset, 1'b0}.
Sends fetch requests to IFU
The FTQ issues a fetch request to the IFU, the ifuPtr pointer increments by one, and it waits for the pre-decoding information to be written back.
The pre-decoding information written back by the IFU is temporarily stored in ftq_pd_mem by the FTQ:
- ftq_pd_mem: Implemented with a register file, storing the decoding information of each instruction within the prediction block returned by the fetch unit, including the following fields:
- brMask: Indicates whether each instruction is a conditional branch instruction.
- jmpInfo: Information about unconditional jump instructions at the end of a prediction block, including their existence, whether they are jal or jalr, and whether they are call or ret instructions.
- jmpOffset: The position of the unconditional jump instruction at the end of the predicted block.
- jalTarget: The jump address of the jal instruction at the end of the prediction block.
- rvcMask Indicates whether each instruction is compressed.
Temporarily stores BPU prediction information and sends it back to BPU for training.
Temporarily stores the prediction information from the BPU.
In addition to being temporarily stored in ftq_pc_mem as mentioned earlier, some prediction information from BPU to FTQ is also stored in ftq_redirect_sram, ftq_pc_mem, and ftb_entry_mem.
- ftq_redirect_sram: Implemented with SRAM, stores prediction information that needs to be restored during redirection, primarily including RAS and branch history-related data. Divided into 3 banks, each with a depth×width of 64×236.
- ftq_meta_1r_sram: Implemented as SRAM, storing other BPU prediction information. The depth × width of the SRAM is 64×256.
- ftb_entry_mem: Implemented with a register file, storing the necessary information of the FTB entry during prediction, used for training new FTB entries after commit. Why store ftb_entry? Because updates to ftb_entry require modifications based on the original entry, and to avoid re-reading the FTB, the ftb_entry is stored in ftb_entry_mem.
The specific implementation mechanisms of various SRAMs/memories in the FTQ are shown in the table below:
| Write Timing (Forward Write) | Update timing (reverse updates, such as redirects, etc.) | Read timing | Data content to be written | Updated data content. | |
|---|---|---|---|---|---|
| ftq_pc_mem | During the S1 stage of the BPU pipeline, it is written when creating a new prediction entry. | Does not exist (The current design is that the FTQ aggregates redirects and sends them to the BPU and IFU. When the BPU re-enqueues the prediction block redirected to the new address, it writes the new block into ftq_pc_mem. The entries in ftq_pc_mem represent the address of the current prediction block and do not include the target, so there is no need to update the mispredicted block.) | Read data is stored into Reg every clock cycle. If IFU does not need to read data from bypass, Reg data is directly connected to Icache and IFU. | startAddr: Prediction block start address. nextLineAddr: Start address of the next cache line for the prediction block. isNextMask: Indicates whether each possible instruction start position in the prediction block falls within the next region aligned by prediction width (① If isNextMask(offset)=0, the current predicted instruction PC does not cross cache lines, then the predicted instruction PC = {startAddr[38,6], startAddr[5,1]+offset,1'b0}. ② If isNextMask(offset)=1, the current predicted instruction PC crosses cache lines, then the predicted instruction PC = {nextLineAddr[38,6], startAddr[5,1]+offset,1'b0}.) fallThruError: Indicates whether there is an error in the predicted next sequential fetch address. | None |
| ftq_meta_1r_sram | S3 stage of the BPU pipeline. | When instructions in an FTQ entry can commit, the metadata is read out and sent to the BPU for training. | The written data packet contains prediction information from 4 predictors. | ||
| ftb_entry_mem | S3 stage of the BPU pipeline. | 1. Backend redirect 2. IFU writes back pre-decoding information 3. IFU pre-decoding detects an error and sends a redirect. | BrSlot: brSlot_offset/lower/tarStat/sharing/validTailSlot: tailSlot_offset/lower/tarStat/sharing/validpftAddr,carry,isCall,isRet,isJalr…… | ||
| ftq_pd_mem | Next cycle of IFU stage F3 pipeline | Continuously reading the data corresponding to the address from commPtr and assigning it to ftbEntryGen. | rvcMaskbrMaskjmpInfojmpOffsetjalTarget |
Send back to BPU for training
When instructions are committed in the backend, the FTQ is notified that the instruction has been committed. Once all valid instructions in an FTQ entry have been committed in the backend, the commPtr pointer increments by one, reads the corresponding information from the storage structure, and sends it to the BPU for training.
In the Kunminghu V2 version, commitStateQueue was used to record the commit
status of instructions within an FTQ entry. Note that this design was incomplete
and violated the update intent of BPU, so it was entirely removed in V3 in
collaboration with the backend.
Each bit in commitStateQueue records whether the instructions in the FTQ entry
have been committed.
Since the backend of V2 recompresses FTQ entries in the ROB, it cannot guarantee the submission of every instruction in an entry or even the submission of every entry. Determining whether an entry is submitted has the following possibilities:
robCommPtris beforecommPtr. This means that the backend has started committing instructions from subsequent entries, and all entries before the one pointed to byrobCommPtrmust have been fully committed.- The last instruction in
commitStateQueueis committed. The commitment of the last instruction in an entry signifies that the entire entry has been fully committed.
Additionally, it is necessary to consider that the backend may issue a flush itself redirect request, meaning the instruction itself needs to be re-executed, such as in cases of exceptions or load replay. In such scenarios, this entry should not be committed to update the BPU, as it would significantly degrade BPU accuracy.
Redirect recovery
After each prediction, the top entry and stack pointer of the RAS are stored in ftq_redirect_sram of the FTQ, and the BPU global history used is stored in the FTQ for misprediction recovery.
Misprediction detected during pre-decode
After the FTQ issues a fetch request to the IFU, the IFU writes back pre-decoding information to the FTQ, and the ifuWbPtr pointer increments by one. If the pre-decoding detects a prediction error, a corresponding redirect request is sent to the BPU. The FTQ restores the bpuPtr and ifuPtr based on the ftqIdx in the redirect signal.
Backend detects misprediction
If an instruction detects a misprediction during backend execution, it notifies the FTQ. The FTQ then sends corresponding redirect requests to the IFU and BPU, and simultaneously restores bpuPtr, ifuPtr, and ifuWbPtr based on the ftqIdx in the redirect signal.
To enable reading the redirect data stored in the FTQ one cycle earlier and reduce redirect penalty, the backend sends the ftqIdxAhead signal and ftqIdxSelOH signal to the FTQ one cycle ahead (relative to the formal backend redirect signal). However, the backend cannot obtain the accurate ftqIdx one cycle early and needs to arbitrate among the four ALU paths. The arbitration result is only available when the formal backend redirect signal is valid, so the FTQ must read all four paths for the ftqIdx signal of the early redirect.
- io.fromBackend.ftqIdxAhead: 7 FtqIdx. Indicates the index of the prediction block stored in the FTQ that requires redirection. There are 7 because the backend has 7 potential paths that may generate redirect signals before final arbitration: Jump1, Alu4, LdReplay1, Exception1. However, only the redirect signals from Alu*4 are read early, so only 4 FtqIdx are actually used for ftqIdxAhead.
- Io.fromBackend.ftqIdxSelOH: 4-bit one-hot code + valid, indicating the validity of ftqIdxAhead for the 4 paths, active high.
Sending prefetch requests to ICache.
Since the BPU is essentially non-blocking, it often advances ahead of the IFU. Therefore, the FTQ implements instruction prefetching by utilizing the fetch requests provided by the BPU that have not yet been issued to the IFU, directly sending prefetch requests to the instruction cache.
Overall Block Diagram
Interface timing
- BPU to FTQ Interface Timing

The above diagram illustrates the timing of the prediction result interface from BPU to FTQ. When the corresponding handshake signals io_fromBpu_resp_valid and io_fromBpu_resp_ready are both high, the prediction results from the three pipeline stages of the BPU are input to the FTQ in stages 1, 2, and 3 of the pipeline.
If the prediction results from later pipeline stages of the BPU do not match those from earlier stages, the corresponding redirect signals io_fromBpu_resp_bits_s2_hasRedirect_4 or io_fromBpu_resp_bits_s3_hasRedirect_4 will be asserted, indicating the need to flush the prediction pipeline.
Functional description
The FTQ is a buffer queue between branch prediction and the fetch unit. Its primary function is to temporarily store fetch targets predicted by the BPU and send fetch requests to the IFU based on these targets. Another key function is to cache prediction information from various BPU predictors and send this information back to the BPU for predictor training after instruction submission. Thus, it needs to maintain the complete lifecycle of instructions from prediction to submission. Since storing PC in the backend is costly, the backend reads from the FTQ when instruction PC is needed.
Internal structure
The FTQ has a total of 64 entries and is structured as a queue. However, the content of each entry is stored in different storage structures based on its characteristics. These storage structures mainly include the following types:
- ftq_pc_mem: Implemented with a register file, storing information related to instruction addresses, including the following fields.
- startAddr Prediction block start address
- nextLineAddr: The starting address of the next cache line in the prediction block.
- isNextMask predicts whether the starting position of each possible instruction is within the next region aligned by the prediction width.
- fallThruError Indicates whether there is an error in the predicted next sequential fetch address.
- ftq_pd_mem: A register file implementation that stores decoded information of instructions within the predicted block returned by the fetch unit, including the following fields.
- brMask: Indicates whether each instruction is a conditional branch.
- jmpInfo Information about the unconditional jump instruction at the end of the prediction block, including its existence, whether it is jal or jalr, and whether it is a call or ret instruction.
- jmpOffset: The position of the unconditional jump instruction at the end of the prediction block.
- jalTarget The jump address of the jal instruction at the end of the prediction block.
- rvcMask: Indicates whether each instruction is a compressed instruction.
- ftq_redirect_sram: SRAM implementation that stores prediction information requiring restoration during redirection, primarily including RAS and branch history-related data.
- ftq_meta_1r_sram: Implemented with SRAM, storing other BPU prediction information.
- ftb_entry_mem: A register file implementation that stores essential information of FTB entries during prediction, used for training new FTB entries after commit.
Additionally, some information such as queue pointers and the status of entries in the queue is implemented with registers.
The lifecycle of instructions in the FTQ
Instructions are sent to FTQ from BPU prediction in units of prediction blocks, and the corresponding entry in the storage structure is only fully released when all instructions in the prediction block have been committed in the backend. The following events occur during this process:
- Prediction blocks are issued from the BPU to the FTQ, the bpuPtr increments by one, initializing various states of the corresponding FTQ entry and writing prediction information into storage structures. If the prediction block comes from BPU's override prediction logic, the bpuPtr and ifuPtr are restored.
- The FTQ sends a fetch request to the IFU, increments the ifuPtr pointer, and waits for the pre-decoding information to be written back.
- IFU writes back pre-decode information, increments the ifuWbPtr pointer. If pre-decode detects a prediction error, it sends a corresponding redirection request to BPU to restore bpuPtr and ifuPtr.
- Instructions proceed to the backend for execution. If the backend detects a misprediction, it notifies the FTQ, which then sends redirect requests to the IFU and BPU to restore bpuPtr, ifuPtr, and ifuWbPtr.
- When instructions are committed in the backend, FTQ is notified. Once all valid instructions in the FTQ entry have been committed, the commPtr increments by one, reads the corresponding information from the storage structure, and sends it to BPU for training.
The lifecycle of instructions in predicted block n involves four pointers in the FTQ: bpuPtr, ifuPtr, ifuWbPtr, and commPtr. The lifecycle begins when bpuPtr starts pointing to n+1 and ends when commPtr points to n+1.
Other Functions of FTQ
Since the BPU is largely non-blocking, it often runs ahead of the IFU. Thus, the fetch requests provided by the BPU that have not yet been sent to the IFU can be used for instruction prefetching. The FTQ implements this logic to directly send prefetch requests to the instruction cache.