BPU Submodule RAS
Glossary of Terms
| Abbreviation | Full name | Descrption |
|---|---|---|
| TOSW | Top Of Speculative Queue Write Pointer | Speculative queue write pointer |
| TOSR | Top Of Speculative Queue Read Pointer | Speculative Queue Read Pointer |
| NOS | Next Older Speculative Queue entry Pointer | Next Older Speculative Queue entry Pointer |
| ssp | Speculative Stack Pointer | Virtual Speculative Stack Pointer |
| nsp | Next Stack Pointer | Commit Stack Pointer |
Function
The RAS predictor employs a stack structure to predict execution flows with paired matching characteristics, such as function calls and returns. Call-type (push/call) instructions are identified by jal/jalr instructions with target register addresses of 1 or 5. Return-type (ret) instructions are characterized by jalr instructions with source registers of 1 or 5.
In the implementation, the RAS predictor provides prediction results in both the s2 and s3 stages.
The RAS predictor in the Kunming Lake architecture differs significantly from that in the South Lake architecture. By introducing a persistent queue, the new RAS predictor structure resolves the issue of predictor data pollution caused by speculative execution in local predictors. At the same time, the new structure retains a stack-like architecture similar to the South Lake architecture as a commit stack, storing post-commit push information to compensate for the low storage density of the persistent queue.
Overview of the RAS Predictor Architecture Based on Persistent Queue Design
The RAS predictor utilizes the local pairing information of call/return instructions within the branch prediction FTB block to make predictions for return instructions. Since a normally called function will return to the instruction following the call upon completion, the RAS predictor can generate a predicted return address for function calls when encountering a call instruction based on the current instruction PC and whether it is an RVC instruction (determining the instruction width as 2 or 4 bytes), then push this prediction onto the stack.
Modern superscalar out-of-order processors typically employ deep pipeline speculative execution techniques. The branch predictor generates predictions for subsequent instructions before the execution results of previously predicted instructions are confirmed. That is, when facing three consecutive branch prediction requests (A, B, C), the RAS predictor cannot obtain the final execution results of instructions within block A when predicting B. Instead, it can only access the final execution results of instructions within block Z of block A and the speculative results between blocks Z and B based on branch predictions. If there are incorrect branch prediction results between blocks Z and B, the branch predictor states involved must be recovered from misprediction. As mentioned earlier, the RAS predictor uses a stack structure to predict call-return instruction pairs, where the accuracy of pairing information is crucial. The most straightforward approach to precisely restore the RAS predictor's state at the misprediction point is to backtrack from the latest prediction point to the misprediction point and undo all modifications made to the RAS stack during this period. However, to improve the timeliness of misprediction recovery, modern processors generally cannot afford such high-complexity operations during recovery. In the Nanhu architecture design, the RAS predictor only restores the top stack entry and the stack pointer corresponding to the mispredicted block during misprediction. This recovery strategy can address contamination of the RAS stack top and above due to speculative execution but cannot handle contamination below the stack top caused by pop-push operations during speculation.
Such contamination can cause subsequent return instructions to jump to incorrect targets, leading to mispredictions. To address this issue, the new RAS predictor in the Kunming Lake architecture introduces a persistence queue to save all local states during speculative execution of RAS, achieving contamination-resistant prediction. Specifically, the stack structure simulated by the persistence queue has three pointers: read pointer TOSR, write pointer TOSW, and bottom pointer BOS. Each entry records its own data and a pointer NOS indicating the previous entry's position in the persistence queue. During each stack push operation, TOSW is advanced to allocate new storage space for the current push data, and the current TOSR points to the original position of TOSW (i.e., the newly allocated space). The NOS of the newly pushed entry stores the read pointer position before the push operation. During each stack pop operation, TOSR is moved to the NOS pointer position of the current TOSR entry. This design allows RAS to traverse all entries of the current version (corresponding to a speculative execution path) via a forward-linked list without overwriting any data from other versions (corresponding to other speculative execution paths).
To enhance the effective storage capacity of RAS, not all RAS entries are stored in the form of a persistent queue. Based on empirical data, a maximum of approximately 28 persistent queue entries are required to meet the needs of speculative execution paths. Thus, the RTL implementation uses a 32-entry persistent queue. After the instructions of a prediction block (i.e., a block containing a call instruction) corresponding to an RAS entry are committed, the block can be released from the persistent queue and moved into the commit stack. This release operation is performed by adjusting the BOS pointer to the TOSW pointer corresponding to the committed prediction block. The commit stack follows the same design as the Nanhu architecture: pushing increases the commit stack pointer nsp and writes the data to the new stack top; popping decreases the stack pointer nsp. Since it only stores deterministic post-commit information, there is no risk of speculative execution pollution. The interval between the original BOS and the new TOSW may contain push results from other erroneous paths in the commit stack, which are naturally released during this BOS movement.
Due to the introduction of two structures—the persistent queue and the commit stack—the top-of-stack item may reside in either one. Dynamic judgment is required when providing prediction results. The persistent queue is a circular queue where each pointer, in addition to its value for addressing, includes a flag bit. This bit helps determine the positional relationships among BOS, TOSW, and TOSR. When TOSR is located above BOS and below TOSW, the top-of-stack item is inside the persistent queue. When TOSR is below BOS, the top-of-stack item is outside the persistent queue, i.e., within the commit stack. Thus, we can dynamically select the top-of-stack item during runtime. Note that the top-of-stack item retrieved from the commit stack does not always align with the top of the committed instructions' stack. Therefore, we need to maintain another commit stack pointer, ssp, for the RAS predictor, which indicates the position of the item in the persistent queue after it is pushed into the commit stack. When accessing the top-of-stack item from the commit stack, ssp is used instead of nsp for data retrieval.
The above discussion assumes the persistence queue has sufficient capacity and does not overflow. If push operations are too frequent and backend execution is slow, the persistence queue may overflow. Two possible solutions exist: forced overwriting or dynamically disabling return stack prediction. The Kunming Lake architecture currently adopts the latter. When BOS and TOSW are about to overlap, BOS is forcibly advanced by one entry to prevent accidental clearing of the persistence queue. Since BOS entries may not be needed during this period, this strategy slightly reduces frontend stalls. The drawback is that frequent push operations on incorrect paths may lead to minor pop errors if overwritten entries are needed, and the causes of such errors are complex. The dynamic disablement approach risks data errors if frequent push operations occur on the correct path, as unrecorded entries may corrupt stack data. Recursive scenarios may mitigate such errors. For controllability, Kunming Lake currently uses the latter approach.
For timing optimization, the reading/updating of the stack top entry is not completed in the same cycle as the read request but is updated in the previous or N-th cycle based on the current push/pop operations. To minimize write operations to the speculative queue, the push/pop results in BPU Stage 2 are not directly written to the speculative queue but are delayed by one cycle. Considering scenarios where data written in the current cycle needs to be read in the next cycle, a write bypass mechanism is designed. The data to be written is first used to update the writeEntry item in the write bypass during the current cycle. If the pointer requested in the next cycle matches the pointer position recorded in the write bypass, the bypass value is used; otherwise, the value read from the stack top is used (this logic is actually advanced to the cycle before reading the stack top for timing optimization).
Stage 2 results.
In BPU stage 2, since the prediction results from other branch predictors are not yet fully determined, there may be prediction results that require updates. The current prediction results are not the final confirmed speculative execution path. The current prediction results assume that the starting address of the branch prediction block in stage 3 at the same time will not change, and other branch instructions located before call/ret instructions will no longer be predicted to jump. If the FTB entry received from the FTB in stage 2 is valid and contains a push-type instruction, the PC value of the next instruction after this instruction is pushed onto the RAS stack. If the FTB entry received from the FTB predictor in stage 2 is valid and contains a pop-type instruction, the address at the top of the stack is returned as the result and popped from the stack.
Within the RAS, the above behavior is decomposed as follows:
When a predicted jump call instruction is detected in the FTB entry at Stage 2, the s2_spec_push signal is raised, and the stack push address information is generated based on the current call instruction's PC, instructing the internal RASStack module to act. Upon detecting a push operation, the RASStack module uses the incoming stack top address as the predicted address for the new entry in the persistent queue. If the new address matches the original address and the original stack top counter is not saturated, the new entry's counter is set to the original counter + 1; otherwise, it is set to 0. The newly generated entry serves three purposes: 1) updating the writeBypassEntry register in the next cycle for continuous prediction stack top reads; 2) updating the stack top entry within the current cycle for continuous prediction reads; 3) being used to update the persistent queue two cycles later. Meanwhile, as described, TOSR is updated to the current TOSW, and TOSW is updated to TOSW + 1. The global ssp and sctr follow a similar counter update algorithm: if the old and new stack top addresses match and the original sctr (same as the original stack top entry's ctr) is not saturated, ssp remains unchanged, and sctr = sctr + 1; otherwise, ssp = ssp + 1, and sctr = 0. To handle potential persistent queue overflow scenarios, the return stack predictor is paused if the persistent queue is nearing overflow.
If a predicted jump call instruction is observed in the FTB entry during stage 2, the s2_spec_pop signal is raised to instruct the internal RASStack module to act. When the RASStack module detects a pop action, if the current sctr is not 0, then sctr = sctr - 1 and ssp remains unchanged; otherwise, ssp = ssp - 1 and sctr is set to the sctr of the new top stack entry. TOSR is set to the NOS of the original top, and TOSW remains unchanged. The separately maintained top stack entry is also updated using the new ssp, sctr, TOSR, and TOSW.
Stage 3 result
If a predicted jump return instruction is seen in the 3-stage FTB entry, the s3_push signal is raised; if a predicted jump call instruction is seen in the 3-stage FTB entry, the s3_pop signal is raised. The prediction results made by the current prediction block in stage 2 are also latched to stage 3 (s3_pushed_in_s2 and s3_poped_in_s2). If the actions determined in stage 2 and stage 3 differ, recovery is required in stage 3. Regardless of recovery, stage 3 uses the RAS stack top entry read in stage 2 as the prediction result.
Because the push/pop operations in Stage 2 and the push/pop operations in Stage 3 only occur in the following scenarios, Stage 3 can undo the operations performed in Stage 2 via push/pop actions.
| S2 push | S3 push | No fix needed |
| S2 push | S3 keep | Fix by pop |
| S2 keep | S3 push | Fix by push |
| S2 keep | S3 keep | No fix needed |
| S2 keep | S3 pop | Fix by pop |
| S2 pop | S3 keep | Fix by push |
| S2 pop | S3 pop | No fix needed |
The specific actions of 3-stage push/pop operations in RASStack are identical to those in the 2-stage process and are not repeated here.
Misprediction state recovery
After the prediction block exits the BPU, redirections may be triggered during execution in the IFU or backend. Upon encountering a redirection, the RAS predictor needs to restore its state. Specifically, the RAS's TOSR, TOSW, ssp, and sctr must be restored according to the corresponding meta information before the misprediction occurred. Subsequently, depending on whether the mispredicted instruction itself is a call/return instruction, the stack structure must be adjusted via push and pop operations. The specific actions for push and pop operations are the same as in the 2nd and 3rd prediction pipeline stages and are omitted here.
Commit entry migration
As described, when a prediction block containing a call instruction is committed, BOS is updated to the TOSW at prediction time. Simultaneously, the entry corresponding to the prediction block is written to the commit stack top (addressed by nsp), and nsp is updated. The nsp update algorithm is similar to ssp: if recursion exists and the stack top counter is not full, counter=counter+1 and nsp remains unchanged; otherwise, nsp=nsp+1 and counter=0.
Overall Block Diagram

Interface timing
RAS Module Stage 2 Update Input/Output Interface
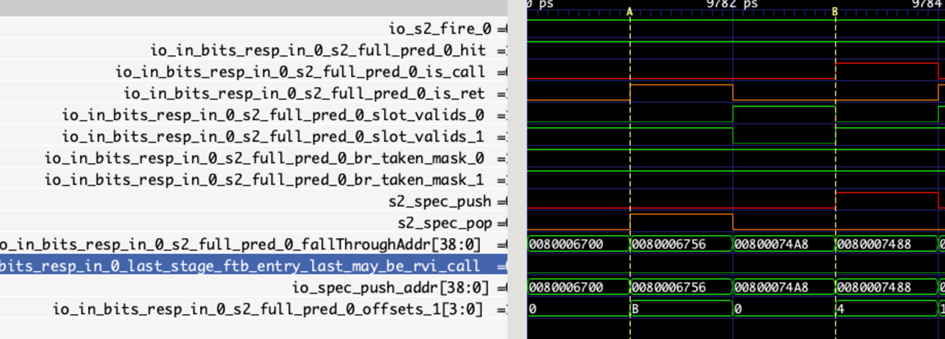
The above figure demonstrates a pop and a push operation in the RAS module's 2-stage update. Since the branch prediction slots before the push and pop blocks are invalid, the pipeline stage observes jumps for return and call instructions, instructing the RASStack module to pop/push accordingly. During push, the FTB's fallThrough address is used as the return address. If the last instruction is a truncated RVI call instruction, the correct return address is this address +2.
RAS Module 3-Stage Update Input/Output Interface
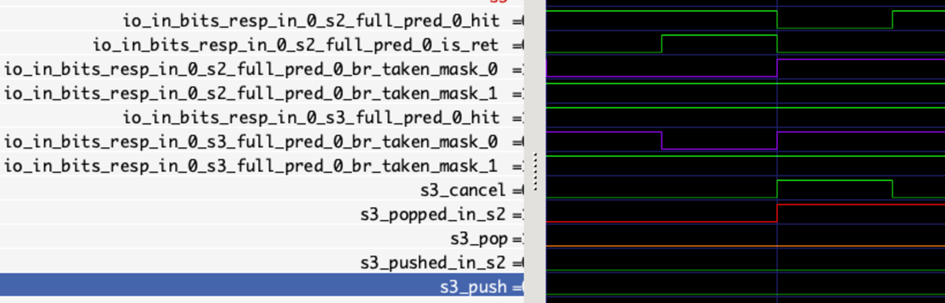
RASStack Module Input Interface

The above diagram shows a push and a pop operation during the Stage 2 update of the RASStack module. It can be observed that after the push operation, the top-of-stack read from the RASStack module is updated to the newly pushed value, while after the pop operation, the top-of-stack reverts to its pre-push value.
RAS module redirection recovery interface
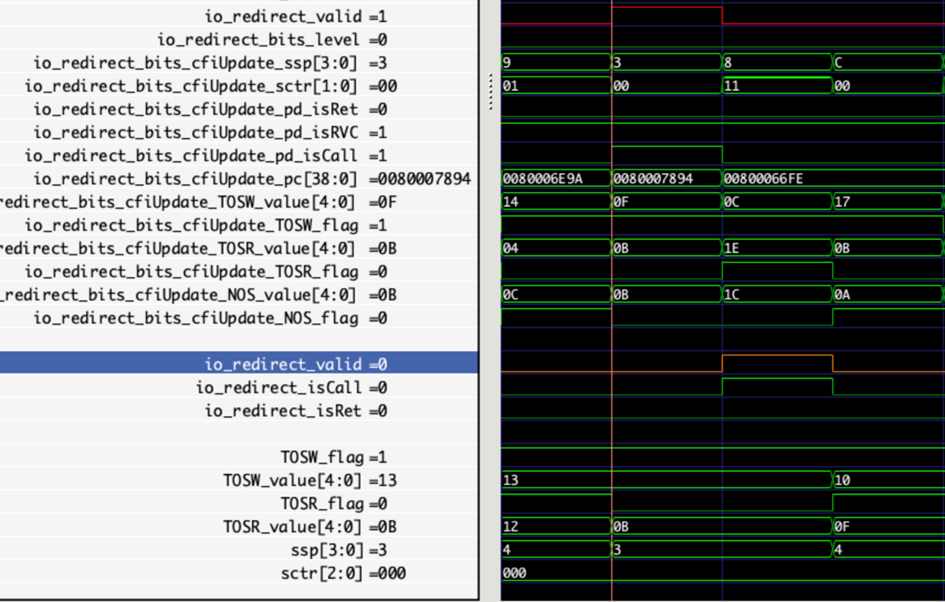
The above diagram illustrates the scenario where the RAS and RASStack modules perform redirection recovery, and the recovery point instruction is a call instruction. The redirection signal from the BPU is delayed by one clock cycle within the RAS predictor before being sent to the RASStack to restore the pointers of each item in the persistent queue. Since the mispredicted instruction is a call instruction, a new entry must also be pushed.
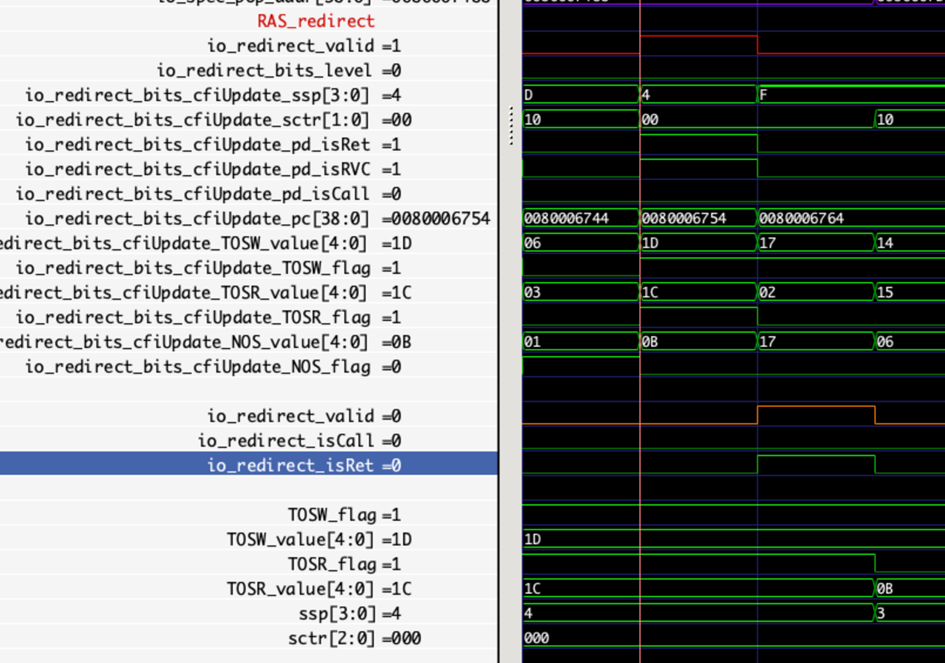
Similarly, if the mispredicted instruction is a return instruction, an entry must be popped from the top of the stack based on the state at that time.
RAS Module Instruction Commit Training Interface
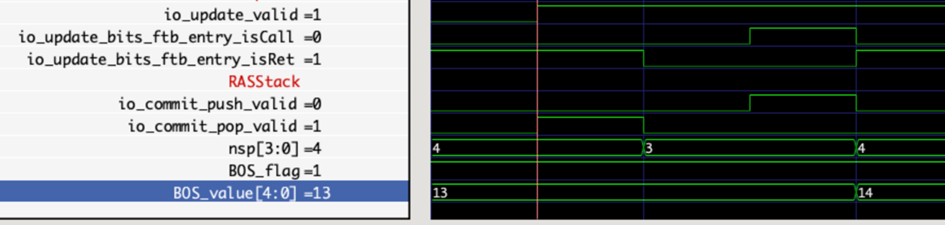
The figure illustrates instruction commits involving one return and one call instruction. It shows that the commit stack top changes during commit, and the BOS pointer is adjusted accordingly after the call instruction is committed.
RAS Storage Structure
The Return Address Stack (RAS) predictor consists of a speculative queue (persistent queue) and a commit stack. The speculative queue has 32 entries, and the commit stack has 16 entries.
The speculative queue entry structure is as follows
| retAddr | sctr | nos |
|---|---|---|
| Return Address | Number of consecutive occurrences of the same return address | Older entry position in the speculative queue |
The commit stack entry structure is as follows:
| retAddr | sctr |
|---|---|
| Return Address | Number of consecutive occurrences of the same return address |
Prediction and Update
The return stack differs from other predictors in that it performs updates simultaneously with predictions. The commit stack is updated when instructions retire. The following diagrams illustrate the operations for obtaining the return stack prediction address, speculative Pop, and speculative Push updates to the speculative queue.
Stack Top Address Retrieval
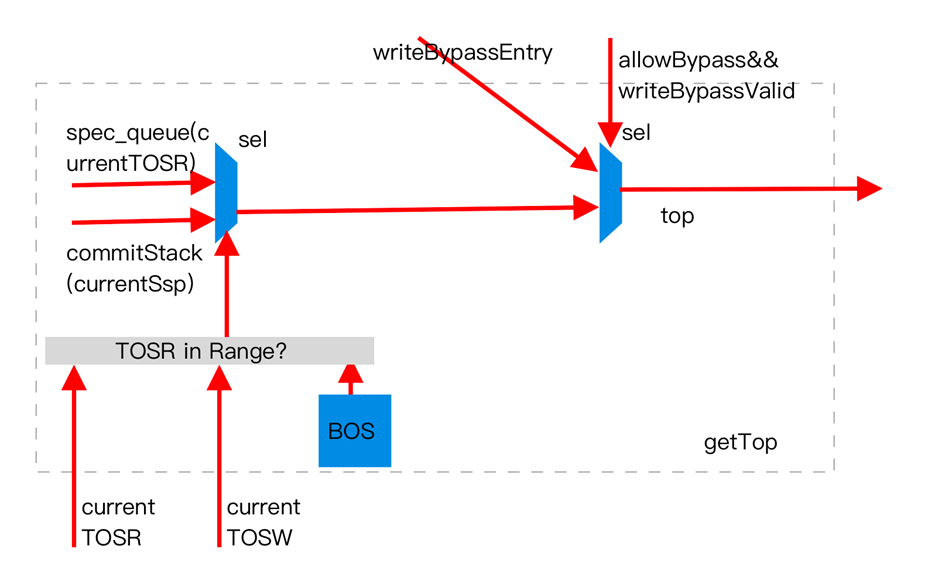
The top data of the return stack may reside in the speculative stack or the commit stack. When the speculative stack is empty, the top data is in the commit stack. The speculative stack and commit stack are maintained using different strategies. The speculative stack is speculative and allows rollback, while the commit stack contains real and valid data that does not allow rollback. The logic for determining if the speculative stack is not empty is BOS <= TOSR < TOSW; otherwise, the speculative stack is empty. (To clarify, during a speculative stack pop, TOSR moves toward BOS. Thus, if TOSR is not within the speculative stack, it indicates the speculative stack is empty. Where does the speculative stack data go? It resides in the commit stack, which is related to the BOS update logic, provided the speculative stack does not overflow.)
Speculative pop
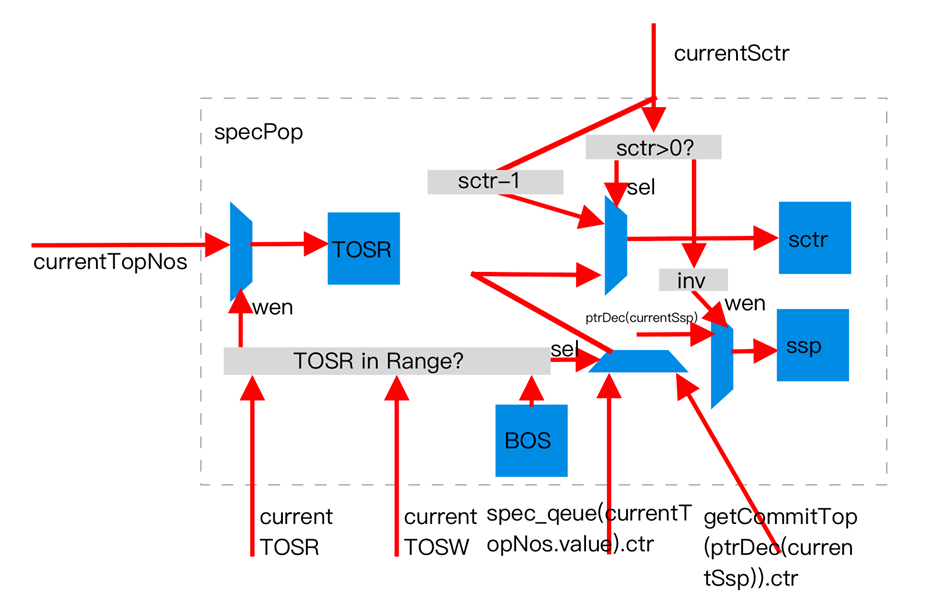
During a speculative stack Pop, only the TOSR pointer is moved to point to the current speculative stack top: TOSR := spec_nos(TOSR). NOS is not updated because each speculative stack entry records its nos point, and moving TOSR inherently updates the current NOS. TOSW remains unchanged to preserve push history for traceability. Another pointer, ssp, records the stack top position during prediction. It is updated based on the original RAS stack results: during a Pop, ssp is decremented by one, though this depends on the sctr value.
Speculative Push
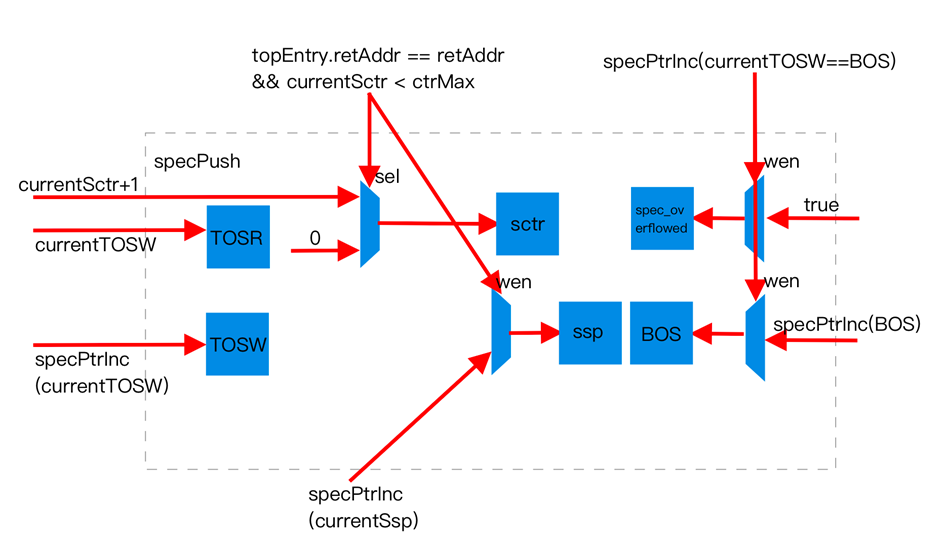
When the speculative stack performs a Push operation, TOSW := TOSW + 1, spec_nos(TOSW) := TOSR, TOSR := TOSW, spec_queue(TOSW) := io.spec_push_addr, ssp = ssp + 1.U. Upon pushing a new entry, TOSW points to the new unallocated entry, TOSR points to the new stack top, and the NOS pointer records the position of the previous stack top, stored in the spec_nos queue for subsequent recovery. The address of the newly pushed entry is recorded in spec_queue. (You might wonder, what if the stack keeps growing indefinitely? --- BOS pointer update and stack overflow handling mechanisms.)
Commit stack update
The update of the commit stack is similar to the conventional return stack structure and will not be elaborated further. A slight difference is that its Push and Pop signals come from the retirement of corresponding call and ret instructions.