XiangShan ICache Design Document
- Version: V2R2
- Status: OK
- Date: 2025/03/07
- commit:4b2c87ba1d7965f6f2b0a396be707a6e2f6fb345
Glossary of Terms
| Abbreviation | Full name | Description |
|---|---|---|
| ICache/I$ | Instruction Cache | L1 instruction cache |
| DCache/D$ | Data Cache | L1 Data Cache |
| L2 Cache/L2$ | Level Two Cache | L2 cache |
| IFU | Instruction Fetch Unit | Fetch Unit |
| ITLB | Instruction Translation Lookaside Buffer | Address Translation Buffer |
| PMP | Physical Memory Protection | Physical Memory Protection Module |
| PMA | Physical Memory Attribute | Physical Memory Attributes module (part of PMP) |
| BEU | Bus Error Unit | Bus error unit |
| FDIP | Fetch-directed Instruction Prefetch | Instruction fetch directs instruction prefetch |
| MSHR | Miss Status Holding Register | Missing state retention register |
| a/(g)pf | Access / (Guest) Page Fault | Access error / (Guest) page fault |
| v/(g)paddr | Virtual / (Guest) Physical Address | Virtual Address / (Guest) Physical Address |
| PBMT | Page-Based Memory Types | Page-based memory types, see the privileged manual for the Svpbmt extension. |
Submodule List
| Submodule | Description |
|---|---|
| MainPipe | Main Pipeline |
| IPrefetchPipe | Prefetch Pipeline |
| WayLookup | Metadata buffer queue |
| MetaArray | Metadata SRAM |
| DataArray | Data SRAM |
| MissUnit | Missing processing unit |
| Replacer | Replacement policy unit |
| CtrlUnit | Control unit, currently only used for error checking/error injection functionality |
Design specifications
- Cache instruction data
- On a miss, request data from L2 via the tilelink bus
- Software maintains L1 I/D Cache coherence (
fence.i) - Supports cross-cacheline fetch/prefetch requests
- Supports flushing (bpu redirect, backend redirect,
fence.i) - Supports prefetch instruction requests
- Hardware prefetching uses the FDIP prefetch algorithm.
- Software prefetching via Zicbop extension
prefetch.iinstruction - Support configurable replacement algorithms
- Supports configurable number of miss status holding registers
- Supports checking address translation errors and physical memory protection errors
- Supports error checking & error recovery & error injection1.
- Parity code is used by default
- Error recovery by refetching from L2
- Error injection control registers accessible by software via MMIO space
- DataArray supports banked storage, achieving low power consumption through fine-grained storage
Parameter List
| Parameters | Default Value | Description | Requirements |
|---|---|---|---|
| nSets | 256 | Number of SRAM sets | Power of 2 |
| nWays | 4 | Number of SRAM ways | |
| nFetchMshr | 4 | Number of fetch MSHRs | |
| nPrefetchMshr | 10 | Number of prefetch MSHRs | |
| nWayLookupSize | 32 | WayLookup depth, which can also backpressure to limit the maximum prefetch distance | |
| DataCodeUnit | 64 | Check unit size, in bits, with 1 check bit per 64 bits. | |
| ICacheDataBanks | 8 | Number of banks per cacheline division | |
| ICacheDataSRAMWidth | 66 | Basic SRAM width of DataArray | Exceeds the sum of data and code width per bank |
Functional Overview
The FTQ stores prediction blocks generated by the BPU, with fetchPtr pointing to the fetch prediction block and prefetchPtr pointing to the prefetch prediction block. Upon reset, prefetchPtr aligns with fetchPtr. Each successful fetch request increments fetchPtr, while each successful prefetch request increments prefetchPtr. For detailed information, refer to the FTQ Design Document.

The ICache structure is shown in the figure below. It has two pipelines: MainPipe and IPrefetchPipe. MainPipe receives instruction fetch requests from FTQ, while IPrefetchPipe receives hardware/software prefetch requests from FTQ/MemBlock. For prefetch requests, IPrefetch queries the MetaArray and stores the metadata (which way hit, ECC check code, whether an exception occurred, etc.) in WayLookup. If the request misses, it is sent to MissUnit for prefetching. For instruction fetch requests, MainPipe first reads the hit information from WayLookup. If no information is available in WayLookup, MainPipe will block until IPrefetchPipe writes the information into WayLookup. This scheme separates access to MetaArray and DataArray, accessing only a single way of DataArray at a time, achieving lower power consumption at the cost of a one-cycle redirect latency.

MissUnit handles fetch requests from MainPipe and prefetch requests from IPrefetchPipe, managed through MSHR. All MSHRs share a set of data registers to reduce area.
Replacer serves as the replacement unit, defaulting to the PLRU replacement policy. It receives hit updates from MainPipe and provides the waymask to be replaced to MissUnit.
MetaArray is divided into odd and even banks to support dual-line accesses across cachelines.
The cacheline in DataArray is divided into 8 banks by default, with each bank storing 64 bits of valid data plus 1 parity bit. Since 65-bit-wide SRAM performs poorly, 256×66-bit SRAM is used as the basic unit, totaling 32 such units. Each access requires 34 bytes of instruction data, necessitating access to 5 banks (8×5 > 34), selected based on the starting address.
Functional Details
(Pre)fetch request
The FTQ sends fetch/prefetch requests to the respective fetch/prefetch pipelines for processing. As mentioned earlier, IPrefetch queries the MetaArray and ITLB, storing metadata (such as hit way, ECC code, exception occurrence, etc.) in WayLookup during the IPrefetchPipe s1 stage for MainPipe s0 to read.
During power-on reset/redirection, since WayLookup is empty and FTQ's
prefetchPtr and fetchPtr reset to the same position, the MainPipe s0 stage has
to stall waiting for the IPrefetchPipe s1 stage to write, introducing an
additional cycle of redirection delay. However, as BPU fills prediction blocks
into FTQ and MainPipe/IFU stalls for various reasons (e.g., miss, IBuffer full),
IPrefetchPipe will work ahead of MainPipe (prefetchPtr > fetchPtr), and
WayLookup will have sufficient metadata. At this point, the MainPipe s0 stage
and IPrefetchPipe s0 stage will operate in parallel.

For detailed instruction fetch procedures, refer to the MainPipe submodule documentation, IPrefetchPipe submodule documentation, and WayLookup submodule documentation.
Hardware prefetch and software prefetch
After V2R2, ICache may accept prefetch requests from two sources:
- Hardware prefetch requests from Ftq, based on FDIP algorithm.
- The software prefetch request from LoadUint in Memblock is essentially the prefetch.i instruction in the Zicbop extension. Please refer to the RISC-V CMO manual.
However, the PrefetchPipe can only process one prefetch request per cycle, necessitating arbitration. The ICache top level is responsible for caching software prefetch requests and selecting between them and hardware prefetch requests from Ftq to send to the PrefetchPipe, with software prefetch requests having higher priority than hardware prefetch requests.
Logically, each LoadUnit can issue a software prefetch request, so there can be
up to the number of LoadUnits (currently the default parameter is LduCnt=3)
software prefetch requests per cycle. However, considering implementation cost
and performance benefits, the ICache can receive and process at most one
software prefetch request per cycle, with any excess being discarded,
prioritizing the one with the smallest port index. Additionally, if the
PrefetchPipe is blocked and the ICache already has a cached software prefetch
request, the original request will be overwritten.
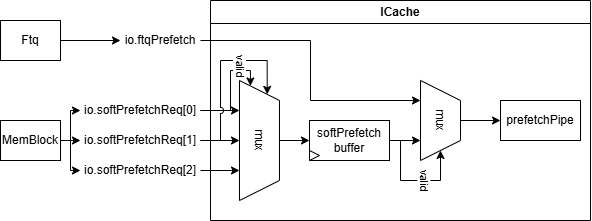
After being sent to the PrefetchPipe, the handling of software prefetch requests is almost identical to hardware prefetch requests, except: - Software prefetch requests do not affect the control flow, meaning they will not be sent to the MainPipe (or subsequent stages like Ifu and IBuffer). They only: 1) determine if there is a miss or exception; 2) if there is a miss and no exception, send to the MissUnit for prefetching and refilling the SRAM.
For details on the PrefetchPipe, refer to the submodule documentation.
Exception propagation/special case handling
The ICache is responsible for performing permission checks on instruction fetch requests (via ITLB and PMP) and handling responses from L2. Potential exceptions during this process include:
| Source | Exception | Description | Process |
|---|---|---|---|
| ITLB | af | Access error occurred during virtual address translation | Disable instruction fetch, mark the fetch block as af, and send it to the backend via IFU and IBuffer for processing. |
| ITLB | gpf | Guest page fault | Disable fetching, mark the fetch block as gpf, and send it to the backend via IFU and IBuffer for processing. The valid gpaddr and isForNonLeafPTE are sent to the backend's GPAMem for potential use. |
| ITLB | pf | Page fault | Disable instruction fetch, mark the fetch block as pf, and send it to the backend for processing via IFU and IBuffer. |
| backend | af/pf/gpf | Same as ITLB af/gpf/pf | Same as ITLB af/gpf/pf |
| PMP | af | Physical address access denied | Same as ITLB af |
| MissUnit | L2 corrupt | L2 cache responds with corrupt | Mark the fetch block as af, send it through IFU and IBuffer to the backend for processing |
It should be noted that for the general instruction fetch process, there is no
such thing as a backend exception. However, to save hardware resources,
XiangShan passes only 41/50 bits of the pc from the frontend (Sv39*4 /
Sv48*4). For instructions like jr and jalr, the jump target comes from a
64-bit register. According to the RISC-V specification, addresses with non-zero
or non-one high bits are illegal and must trigger an exception. This check can
only be performed by the backend and is sent to the Ftq along with the backend
redirect signal, then forwarded to the ICache with the fetch request. This is
essentially an ITLB exception, hence its description and handling are the same
as ITLB.
Additionally, L2 cache responses via the tilelink bus may indicate corruption
due to either L2 ECC errors (d.corrupt) or denied access resulting from
unauthorized bus address space access (d.denied). The tilelink specification
mandates that asserting d.denied must simultaneously assert d.corrupt. Both
scenarios require marking the instruction fetch block as an access fault, so the
ICache currently does not need to distinguish between them (i.e., there is no
need to monitor d.denied, which may be automatically optimized away by Chisel
and thus invisible in the Verilog output).
These exceptions have priorities: backend exception > ITLB exception > PMP exception > MissUnit exception. This is natural: 1. When a backend exception occurs, the vaddr sent to the frontend is incomplete and invalid, making the ITLB address translation process meaningless, and the detected exception invalid. 2. When an ITLB exception occurs, the translated paddr is invalid, rendering the PMP check process meaningless, and any detected exceptions are invalid. 3. When a PMP exception occurs, the paddr has no access permission, and no (pre)fetch request is sent, so no response will be received from the MissUnit.
For the three types of exceptions in the backend and the three types of exceptions in the ITLB, the backend and ITLB internally perform prioritized selection to ensure that at most one is raised at any time.
Additionally, certain mechanisms may trigger special cases, referred to as
exceptions in older documentation/code, though they do not actually cause
exception as defined in the RISC-V manual. To avoid confusion, these will
henceforth be called special cases:
| Source | Special Cases | Description | Process |
|---|---|---|---|
| PMP | mmio | Physical address is in MMIO space | Disable fetching, mark the fetch block as mmio, and perform non-speculative fetching by IFU |
| ITLB | pbmt.NC | Page attributes are non-cacheable and idempotent | Disable instruction fetching, allowing the IFU to perform speculative fetching. |
| ITLB | pbmt.IO | Page attributes are non-cacheable and non-idempotent | PMP MMIO |
| MainPipe | ECC error | Main pipeline detects ECC errors in MetaArray/DataArray | See ECC section; the old version is the same as ITLB af, while the new version performs automatic retry. |
Low-power design of DataArray with bank partitioning
Currently, each cacheline in the ICache is divided into 8 banks, bank0-7. A fetch block requires 34B of instruction data, so each access spans 5 consecutive banks. There are two scenarios:
- These 5 banks are located within a single cacheline (starting address in bank0-3). Assuming the starting address is in bank2, the required data is located in bank2-6. As shown in Figure a.
- Cross-cacheline (starting address located in bank4-7). Assuming the starting address is in bank6, the data is located in bank6-7 of cacheline0 and bank0-2 of cacheline1. Somewhat similar to a ring buffer. As shown in Figure b.

When obtaining a cacheline from SRAM or MSHR, the data is placed into the corresponding bank based on the address.
Since each access only requires data from 5 banks, the port from ICache to IFU actually needs only one 64B port. The respective banks of two cachelines are selected and concatenated before being returned to IFU (completed within the DataArray module). IFU then duplicates and concatenates this 64B data, allowing direct selection of the fetch block data based on the fetch block's starting address. The following diagram illustrates both non-crossing and crossing scenarios:


You may also refer to the comments in IFU.scala.
Flush
When backend/IFU redirection, BPU redirection, or fence.i instruction
execution occurs, the storage structures and pipeline stages in the ICache need
to be flushed as appropriate. Possible flush targets/actions include:
- All pipeline stages of MainPipe and IPrefetchPipe
- During flush, simply set
s0/1/2_validtofalse.B.
- During flush, simply set
- Valid in MetaArray
- During flushing, directly set
validtofalse.B. tagandcodedo not need to be flushed, as their validity is controlled byvalid.- Data in DataArray does not require flushing as their validity is
controlled by
validin MetaArray
- During flushing, directly set
- WayLookup
- Read/write pointer reset
gpf_entry.validis set tofalse.B
- All MSHRs in the MissUnit
- If the MSHR has not yet issued a request to the bus, directly invalidate
it (
valid === false.B) - If the MSHR has already issued a request to the bus, mark it for flushing (flush === true.Borfencei === true.B), and invalidate it only when the d-channel receives a grant response, without returning the grant data to MainPipe/PrefetchPipe or writing it to SRAM - Note that when the d-channel receives a grant response while also receiving a flush (io.flush === true.Borio.fencei === true.B), the MissUnit similarly does not write to SRAM, but will return the data to MainPipe/PrefetchPipe to avoid introducing port latency into the response logic. At this time, MainPipe/PrefetchPipe also simultaneously receives the flush request and will discard the data.
- If the MSHR has not yet issued a request to the bus, directly invalidate
it (
Flush targets required for each flush reason:
| Flush reason | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| Backend/IFU Redirect | Y | Y | Y | |
| BPU redirection | Y2 | |||
fence.i |
Y3 | Y | Y3 | Y |
When the ICache is being flushed, it does not accept fetch/prefetch requests
(io.req.ready === false.B).
Flushing the ITLB
ITLB flushing is unique—its cached page table entries only need flushing upon
executing the sfence.vma instruction. This flushing path is managed by the
backend, so the frontend/ICache generally does not handle ITLB flushing. There
is one exception: to save resources, the ITLB does not store gpaddr. Instead,
it fetches from the L2TLB when a gpf occurs, with the refetch state controlled
by a gpf cache. This requires the ICache to ensure one of the following
conditions when receiving ITLB.resp.excp.gpf_instr:
- Resend the same
ITLB.req.vaddruntilITLB.resp.missis pulled low (at which pointgpf,gpaddrare all valid and can be sent to the backend for normal processing). The ITLB will then flush thegpfcache. - For
ITLB.flushPipe, the ITLB flushes thegpfcache upon receiving this signal.
If the ITLB's gpf cache is not flushed before receiving a request with a
different ITLB.req.vaddr, and another gpf occurs, it will cause the core to
hang.
Therefore, whenever flushing the s1 pipeline stage of IPrefetchPipe, regardless
of the flush reason, it is necessary to synchronously flush the gpf cache of
ITLB (i.e., assert ITLB.flushPipe).
ECC
First, it should be noted that the ICache, with default parameters, uses parity
code, which only has 1-bit error detection capability and no error recovery
capability. Strictly speaking, it cannot be considered ECC (Error Correction
Code). However, on one hand, it can be configured to use secded code; on the
other hand, we extensively use ECC in the code to name error detection and
recovery-related functions (ecc_error, ecc_inject, etc.). Therefore, this
document will still use the term ECC to refer to error detection, recovery, and
injection functions to maintain consistency with the code.
The ICache supports error detection, error recovery, and error injection, which are part of the RAS4 capability. Refer to the RISC-V RERI5 manual for details, controlled by the CtrlUnit.
Error Detection
When MissUnit refills data into MetaArray and DataArray, it calculates checksums for both meta and data. The former is stored in Meta SRAM along with the metadata, while the latter is stored in a separate Data Code SRAM.
When a fetch request reads from SRAM, the check code is also read synchronously.
The meta/data are verified in the s1/s2 stages of the MainPipe, respectively.
Software can enable/disable this feature by writing specific values to the
corresponding CSR bits. In versions from June to December, this is a custom CSR
sfetchctl, which will later be replaced by mmio-mapped CSRs. For details,
refer to the CtrlUnit documentation.
In terms of error-checking code design, the ICache uses a configurable error-checking code, with the default being parity code, where the code is the XOR reduction of the data: \(code = \oplus data\). During verification, the code and data are XOR-reduced together: \(error = (\oplus data) \oplus code\). A result of 1 indicates an error, while ** assumes no ** error (even-numbered errors may occur but cannot be detected here).
In versions after #4044,
the ICache supports error injection, which requires the ICache to support
writing incorrect check codes to MetaArray/DataArray. Therefore, a poison bit
is implemented. When this bit is set high, it flips the written code, i.e.,
\(code = (\oplus data) \oplus poison\).
To reduce undetectable cases, the data is currently divided into DataCodeUnit (default 64-bit) units for separate parity checks. Therefore, for each 64B cache line, a total of \(8(data) + 1(meta) = 9\) check codes will be calculated.
When the s1/s2 pipeline stages of MainPipe detect an error, the following actions are taken:
In versions from June to November:
- Error handling: Triggers an access fault exception, handled by software.
- Error reporting: Reports errors to BEU, which will trigger an interrupt to notify the software of the error.
- Cancel request: When an error is detected in MetaArray, the read ptag is unreliable, making the hit determination unreliable. Thus, regardless of hit status, no request is sent to L2 Cache. Instead, the exception is directly forwarded to IFU and subsequently to the backend for handling.
In subsequent versions (after #3899), an automatic error recovery mechanism was implemented, so only the following processing is required:
- Error Handling: Refetch from L2 Cache, see next section.
- Error reporting: Same as above, reported to the BEU.
Automatic Error Recovery
Note that, unlike the DCache, the ICache is read-only, meaning its data cannot be dirty. This implies we can always retrieve the correct data from lower-level storage structures (L2/3 Cache, memory). Therefore, the ICache can automatically recover from errors by reissuing miss requests to the L2 Cache.
Implementing the refetch functionality itself only requires reusing the existing miss fetch path, following the request path of MainPipe -> MissUnit -> MSHR --tilelink-> L2 Cache. When MissUnit refills data to SRAM, it naturally calculates and stores new check codes, so after refetching, it returns to an error-free state without additional processing.
The pseudo-code illustrating the behavioral differences between June-November and subsequent code is as follows:
- exception = itlb_exception || pmp_exception || ecc_error
+ exception = itlb_exception || pmp_exception
- should_fetch = !hit && !exception
+ should_fetch = (!hit || ecc_error) && !exception
Note: To avoid multi-hit (i.e., multiple ways in the same set having the same ptag) after refetch, the valid bits of the corresponding positions in metaArray must be cleared before refetching:
- If the MetaArray is faulty: the ptag stored in meta may be incorrect, the hit result (one-hot waymask) is unreliable, and the "corresponding position" refers to all ways in that set.
- If DataArray error: Hit result is reliable. "Corresponding position" refers to the way in the set where waymask is asserted.
Error Injection
According to the RERI manual5, to enable software testing of ECC functionality and better assess hardware correctness, error injection capabilities must be provided to actively trigger ECC errors.
The error injection feature of ICache is controlled by CtrlUnit, triggered by writing specific values to the corresponding bits in mmio-mapped CSRs. For details, refer to the CtrlUnit documentation.
Currently, the ICache supports:
- Inject to a specific paddr; injection fails if the requested paddr misses
- Inject into MetaArray or DataArray
- Injection fails when ECC verification itself is not enabled
The software injection process is illustrated as follows:
inject_target:
# maybe do something
ret
test:
la t0, $BASE_ADDR # 载入 mmio-mapped CSR 基地址
la t1, inject_target # 载入注入目标地址
jalr ra, 0(t1) # 跳转到注入目标以保证其加载到 ICache
sd t1, 8(t0) # 向 CSR 写入注入目标地址
la t2, ($TARGET << 2 | 1 << 1 | 1 << 0) # 设置注入目标、注入使能、校验使能
sd t1, 0(t0) # 向 CSR 写入注入请求
loop:
ld t1, 0(t0) # 读取 CSR
andi t1, t1, (0b11 << (4+1)) # 读取注入状态
beqz t1, loop # 如果注入未完成,继续等待
addi t1, t1, -1
bnez t1, error # 如果注入失败,跳转到错误处理
jalr ra, 0(t1) # 注入成功,跳转到注入目标地址以触发错误
j finish # 结束
error:
# handle error
finish:
# finish
We have written a test case, see this repository, which tests the following scenarios:
- Normal injection into MetaArray
- Normal injection into DataArray
- Inject invalid target
- Injected but ECC check not enabled
- Inject the missed address
- Attempt to write to a read-only CSR field.
References
- Glenn Reinman, Brad Calder, and Todd Austin. "Fetch directed instruction prefetching." 32nd Annual ACM/IEEE International Symposium on Microarchitecture (MICRO). 1999.
-
This document also refers to error checking & error recovery & error injection related functions as ECC. See the explanation at the beginning of the ECC section in . ↩
-
The BPU precise predictor (BPU s2/s3 provides results) may override the prediction of the simple predictor (BPU s0 provides results). Clearly, its redirect request arrives at the ICache at the latest 1-2 cycles after the prefetch request, so only the following is needed:
BPU s2 redirect:冲刷 IPrefetchPipe s0
BPU s3 redirect:冲刷 IPrefetchPipe s0/1
当 IPrefetchPipe 的对应流水级中的请求来自于软件预取时
isSoftPrefetch === true.B,不需要进行冲刷当 IprefetchPipe 的对应流水级中的请求来自于硬件预取,但
ftqIdx与冲刷请求不匹配时,不需要进行冲刷 ↩ -
fence.ilogically requires flushing the MainPipe and IPrefetchPipe (as the data in the pipeline may be invalid at this point), but in practice,io.fenceibeing asserted is always accompanied by a backend redirect, making it unnecessary to flush the MainPipe and IPrefetchPipe in the current implementation. ↩↩ -
This RAS (Reliability, Availability, and Serviceability) is not that RAS (Return Address Stack). ↩
-
RERI (RAS Error-record Register Interface), refer to RISC-V RERI Manual. ↩↩